
関連するソリューション

マネージドサービス(運用・保守)
先端技術部
エバンジェリスト 松岡 政之 
こんにちは。先端技術部エバンジェリストの松岡です。
今回は若干長めな内容なのでいきなり本題に入っていきたいと思います。
1.はじめに
今までAWSのインフラ系のサービスについて紹介してきましたが、今回は趣向を変えて機械学習のサービスについて紹介していきたいと思います。機械学習と聞くと専門の方以外は難しいと感じるかもしれません。正直私も詳しくないので難しいものという印象はあります。しかし、今回紹介するサービスは、機械学習について理解していなくても利用できるものです。
というわけで今回ご紹介するはAmazon Kendraというサービスです。皆様ご存じでしょうか?検索サービスや機械学習等に興味がある方以外には、あまり知られていないサービスかもしれません。AWSの公式サイトを見ると機械学習を利用したインテリジェント検索サービスと書かれています。
サービス自体は2019年12月に発表され、2020年4月に一般利用が可能になりました。(※外部サイト:Amazon Kendra が一般利用可能に )また、2021年10月には日本語対応もされたようです。ただし、残念ながらまだ東京リージョンでは利用できません。(※外部サイト:Amazon Kendra は 34 言語のサポートを開始)
具体的に何ができるサービスなのかというと、取り込んだデータから目的のコンテンツを容易に検索することができます。キーワードで検索できるサービスは多々ありますがAmazon Kendraの一番の特徴として、「インスタンスの起動方法は?」といったような自然言語での質問に回答を得られるという点があります。キーワード検索の場合は同じキーワードを含む全く関係ない資料がヒットするとその中からさらに手動で精査する必要がありますが、自然言語での質問に対する回答が正しく得られればより期待する回答を得られる可能性は高くなります。
このサービスを社内や顧客向けのサポートデスクに利用することで、社員が自身で資料を探す時間やサポートデスクにかける人的リソースの低減が期待できます。
また、サポートデスクだけでなく例えば私のようなエンジニアでも過去案件で使用した技術や設計、製品の仕様等について、過去の膨大なドキュメントから探したい場合などにも使えるかもしれません。現状として設計書等に書き記してはいるものの、目的の情報を探し出すのに難儀したり、担当者が替わって引継ぎに漏れがあったりすると、とそもそも必要な情報がどこにあるのかわからなくなることも多々あります。そんな時に、Amazon Kendraを使って素早く検索出来ればより効率的に業務を遂行できるのではないでしょうか?
そこで、今回は実際にAmazon Kendraにインデックスを作成してみて、どのような精度で回答を得られるのか試してみたいと思います。英語でのAmazon Kendraの検証については既に記事にされている方が複数いらっしゃいましたので、今回は日本語対応がどこまで進んでいるのか確認していきたいと思います。ちなみに英語の場合は自然言語での質問に結構な精度で回答を返してくれます。
2.環境準備
2.1 料金
では、環境を作る前に軽く料金についてみていきましょう。Amazon KendraではDeveloper EditionとEnterprise Editionの2つのエディションがあります。基本料金はDeveloper Editionが1.125USD/時間、Enterprise Editionが1.4USD/時間です。1か月使い続けるとそれぞれ810USD、1,008USDと割といいお値段するので個人で使うというよりエンタープライズ向けを意識したサービスでしょう。
エディションによる詳細な違いについては公式ドキュメントをご参照いただくとして、ざっくりいうとインデックス化できるドキュメントの容量や冗長化の有無、拡張性等に差があります。基本的にはDeveloper Editionは検証用、Enterprise Editionは本番環境用といった感じですね。
※外部サイト:Amazon Kendra料金表
2.2 制限事項
冒頭で日本語対応と書きましたが、英語以外の言語に関しては一部制限事項があるのでご注意ください。以下は公式ドキュメント ※外部サイト:Amazon Kendra Developer Guideからの引用です。
Not all Amazon Kendra features are currently available for languages other than English. The following features are not available for non-English indexes:
- Semantic search of FAQs and extracted answers from documents. Keyword search is used for retrieving relevant FAQs and for document ranking.
- Custom synonyms for domain-specific, business-specific, or specialized terms.
- Query suggestions of popular queries relevant to a search.
- Confidence scores in the search results.
要約すると、回答の抽出や用語のカスタム、結果のスコア付け等にはまだ対応していないようです。
2.3 インデックスの作成
それでは早速インデックスの作成を行ってみましょう。
東京リージョンではまだサービス提供がされていないので今回はバージニア北部リージョンを使用します。
インデックスの作成画面は以下のような画面です。東京リージョンで使えないのもあって項目の日本語対応はまだしていませんが、あまり悩むような項目はありません。とりあえず暗号化ができるようなのでデフォルトキーで暗号化をしてみます。
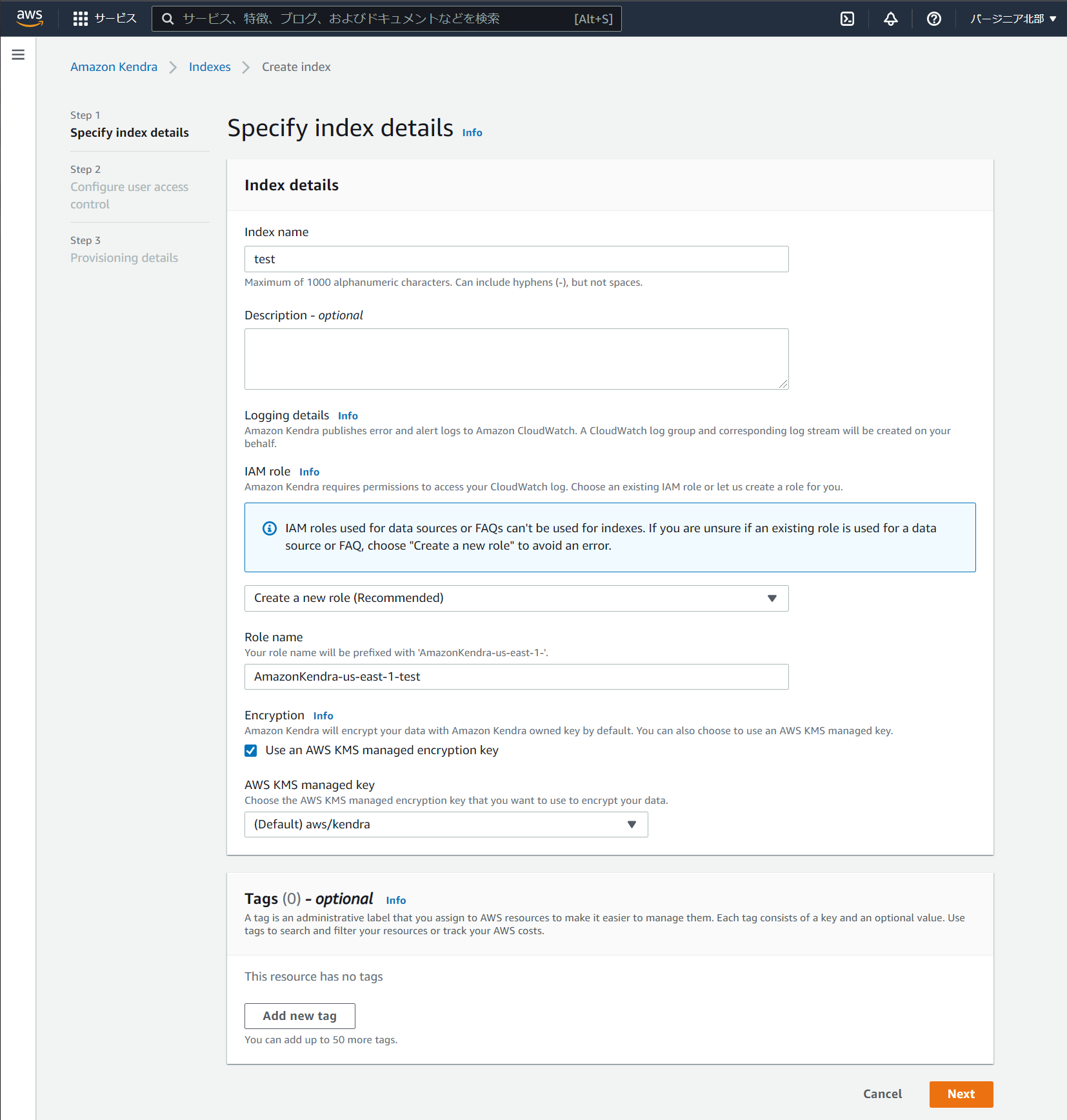
今回は検証ですので特に設定はしません。
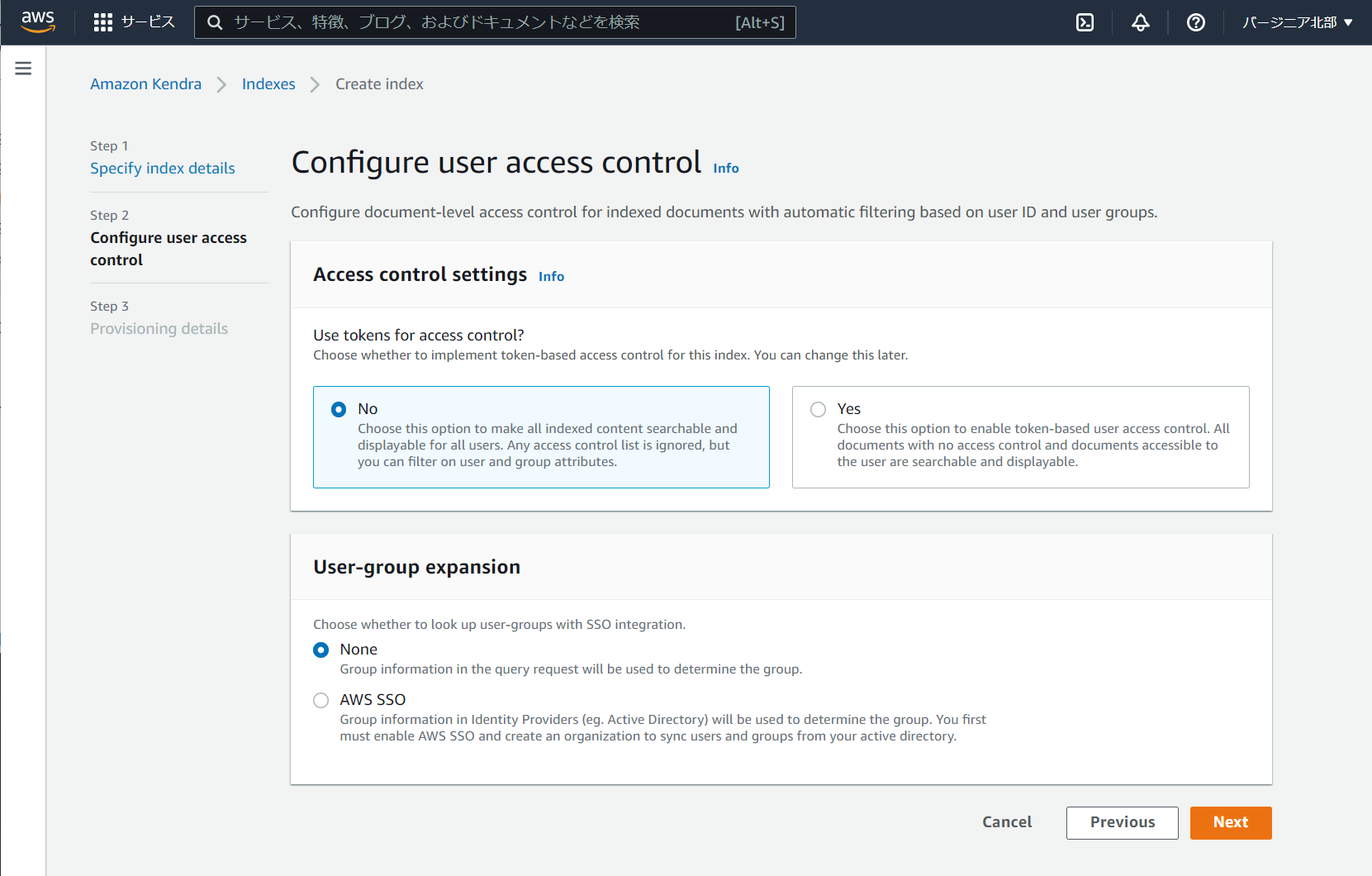
その次はエディションの選択です。用途に合わせて適切なものを選択しましょう。今回は検証なのでDeveloper editionを選択します。
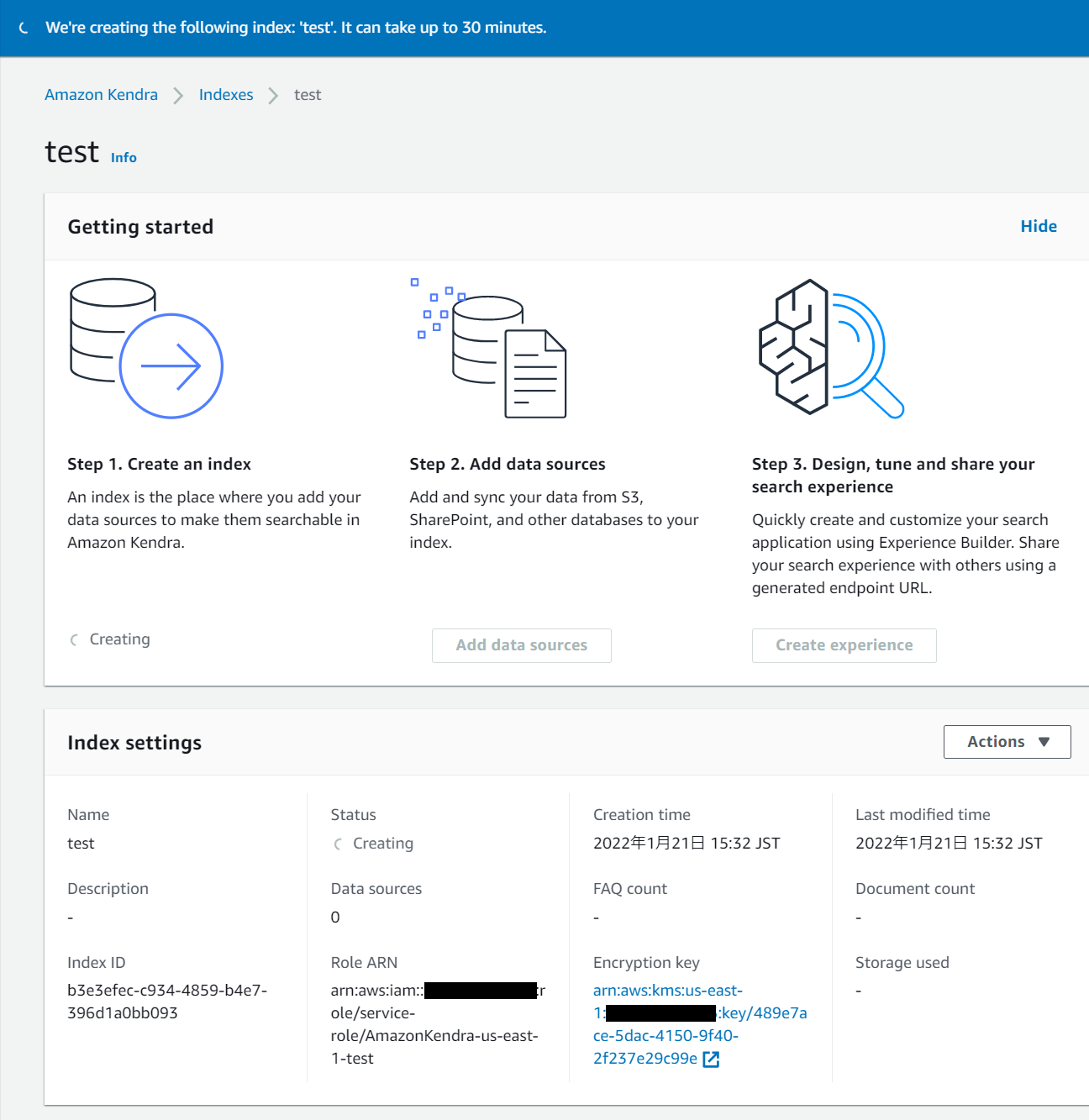
Createをクリックするとインデックスの作成が開始されます。下図にあるように作成にはしばらく時間がかかります。お茶でも飲みながらまったり待つのもいいですが、この間にデータソースの準備を進めていきましょう。
2.4 データソース
Amazon Kendraでインデックスを作成する場合に、データソース(取り込み元)としてAWSだけに限らず様々なサービスを対象とできます。利用できるサービスの一覧については公式サイトをご確認いただくとして、今回はお手軽なAmazon S3のコネクタを試してみたいと思います。
※外部サイト:Amazon Kendra Connector
データの取り込み
ではインデックスの作成を待っている間にAmazon KendraのデータソースとしてS3バケットを準備していきましょう。今回はバージニア北部リージョンでAmazon Kendraを利用しているためS3バケットもバージニア北部リージョンに作成します。そして、検索対象としたいドキュメントをアップロードします。今回はEC2、IAM、S3のユーザガイドを検索対象として試していきます。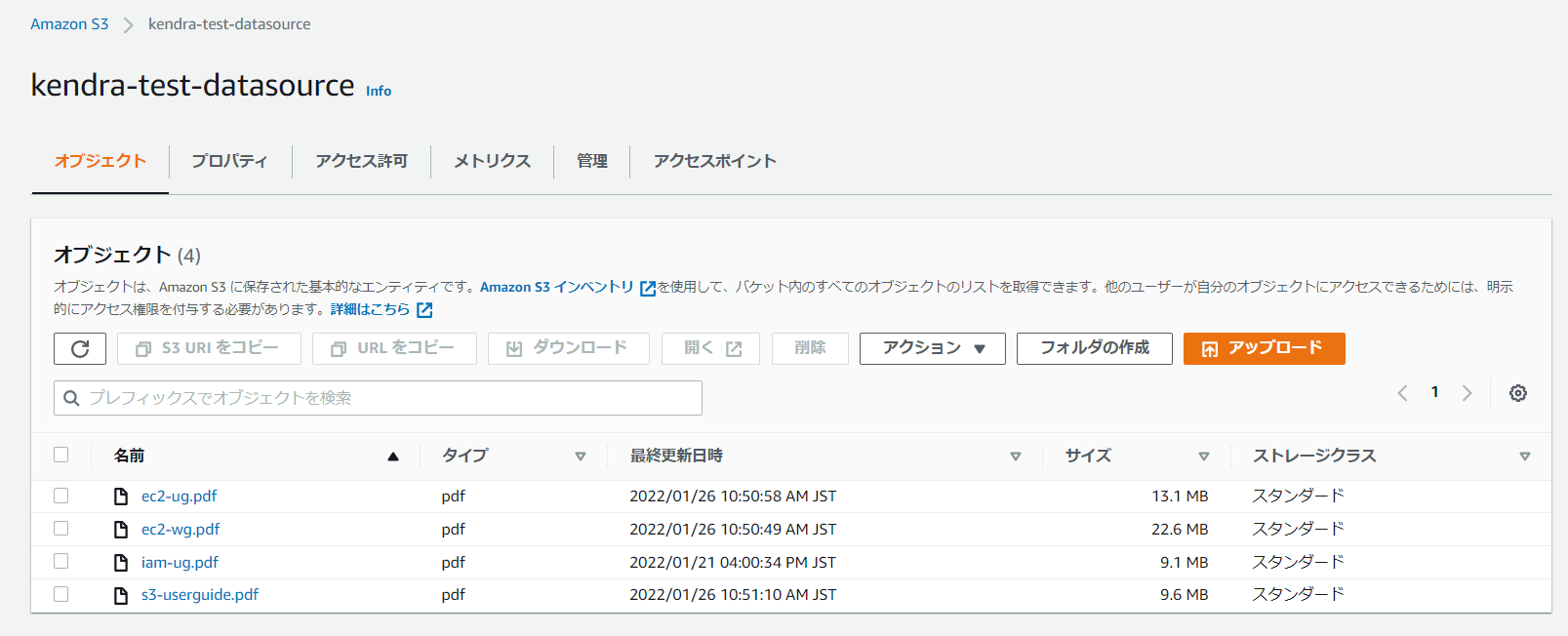
それではAdd data sourcesからAmazon S3のコネクタを選択して追加していきます。
最初の画面では名前等を設定していきますが、ここで重要なのはLanguageの項目でしょう。今回は日本語のドキュメントを利用するのでJapanese(ja)を選択します。
その次の画面ではデータソースとするS3バケットのS3 URIを指定します。簡単ですね。あとはSync run scheduleの項目でAmazon Kendraのインデックスをデータソースに同期させる頻度を選択することができます。データソース内のデータの更新を自動的に反映したい場合は設定すると良いでしょう。そうでない場合はRun on demandに設定し、任意のタイミングで同期ボタンをポチっと押しましょう。今回はRun on demandで設定します。
Sync run scheduleをRun on demandに設定した場合はデータソースを作成してもすぐに同期されません。そのため手動でScan nowをクリックして同期をする必要があります。
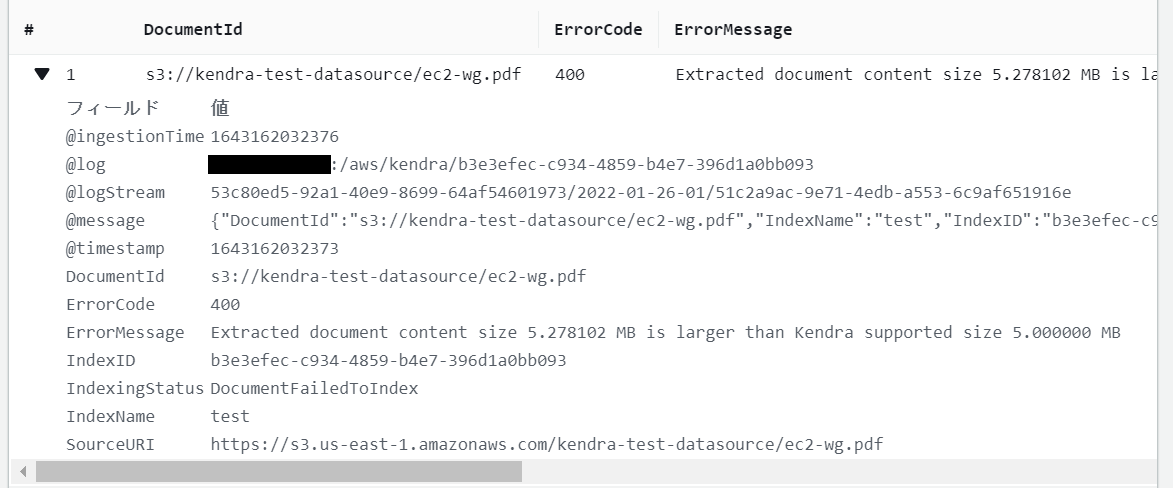
同期の結果はSync historyの項目で見ることができます。今回は4つのユーザガイドの内2つのファイルで無事同期が完了し、2つのファイルが失敗してしまいました。そこでFailedの値をクリックするとエラーを抽出するクエリが入力された状態のCloudWatch Logsのログのインサイトの画面に遷移します。そのため、自分でログファイルを一から漁ることなく容易になぜ失敗したのかを確認することができます。
下図はそのエラーの一例ですが、対象ドキュメントのコンテンツの容量が5MBを越えていたことが問題だったようです。わかりにくいのがファイル自体のサイズではなくそのコンテンツのサイズなのでファイルサイズが9MB程のPDFは取り込みに成功しています。実際に取り込んでみないとわかりにくい部分かと思いますので、Amazon Kendraを運用する場合は同期に失敗していないか逐次監視する必要があるかもしれません。今回は大きいPDFは分割して2つのファイルにすることで無事取り込むことができました。
3.インデックスの検索
3.1 検索例(1)
ここまでの準備でドキュメントのインデックス化が完了し検索する準備ができました。それでは早速検索を試してみたいと思います。
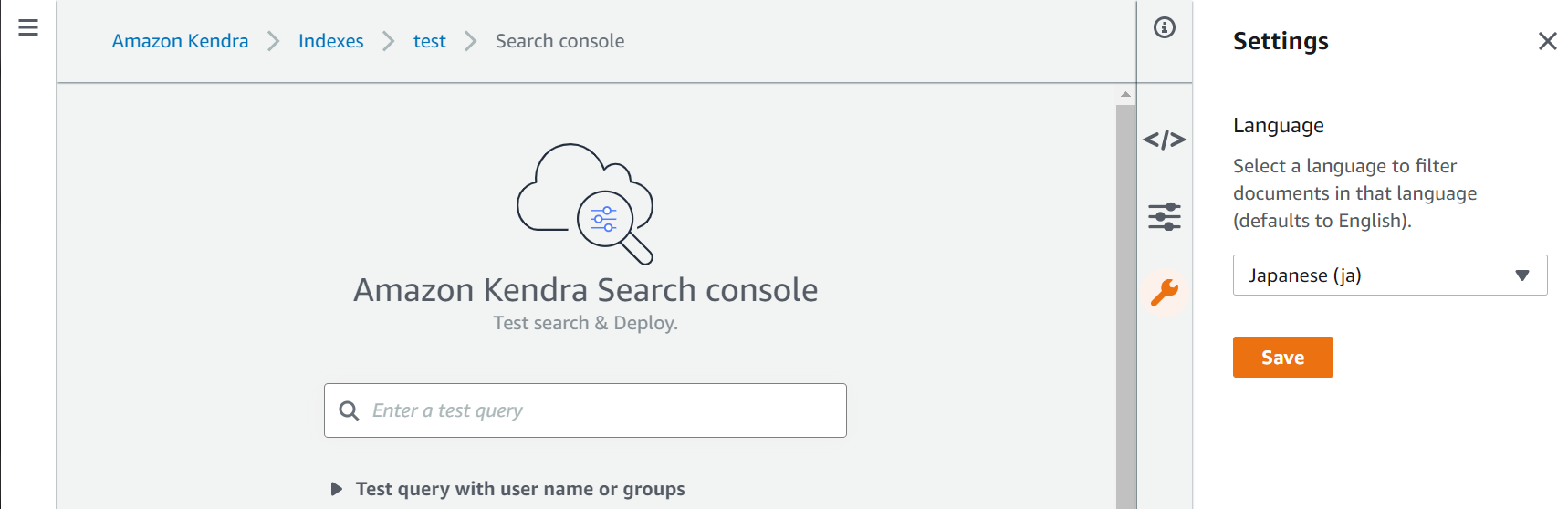
ですがその前に、検索画面のスパナマークから言語設定が日本語になっているか確認しておきましょう。ここが間違っていると日本語で検索してもヒットしないのでご注意ください。
それでは最初に試す検索ワードは「IAMユーザの作成方法は?」でIAMユーザの作成方法を尋ねてみます。その結果が下図の通りです。
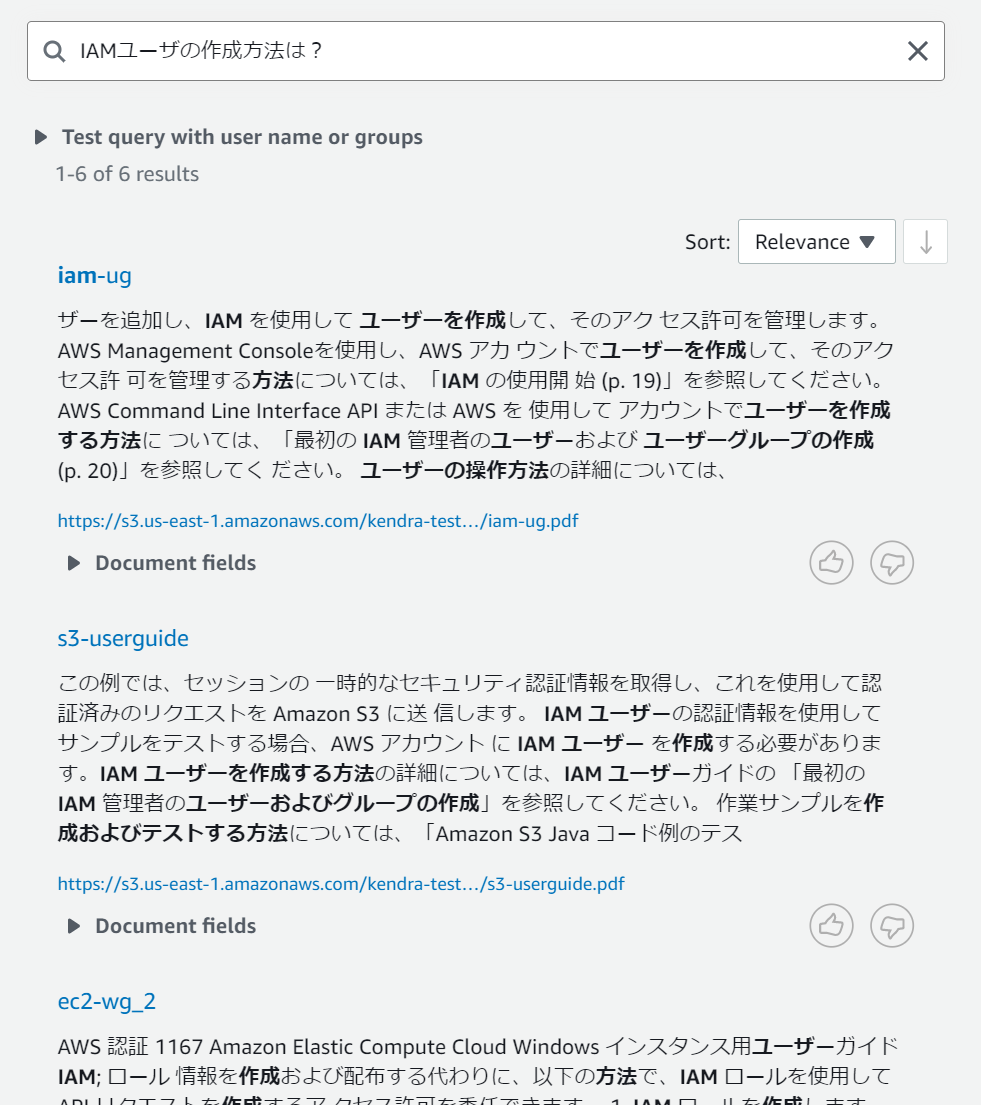
また、上記の通り単語レベルでは正しい区切りで検出されていることや、「は?」といったキーワードでヒットしていないところを見るとある程度日本語として理解して結果を返してくれているようです。
3.2 検索例(2)
続いては「インスタンスへのIAMロールのアタッチ方法は?」とより具体的な質問をしてみます。その結果が下図の通りです。
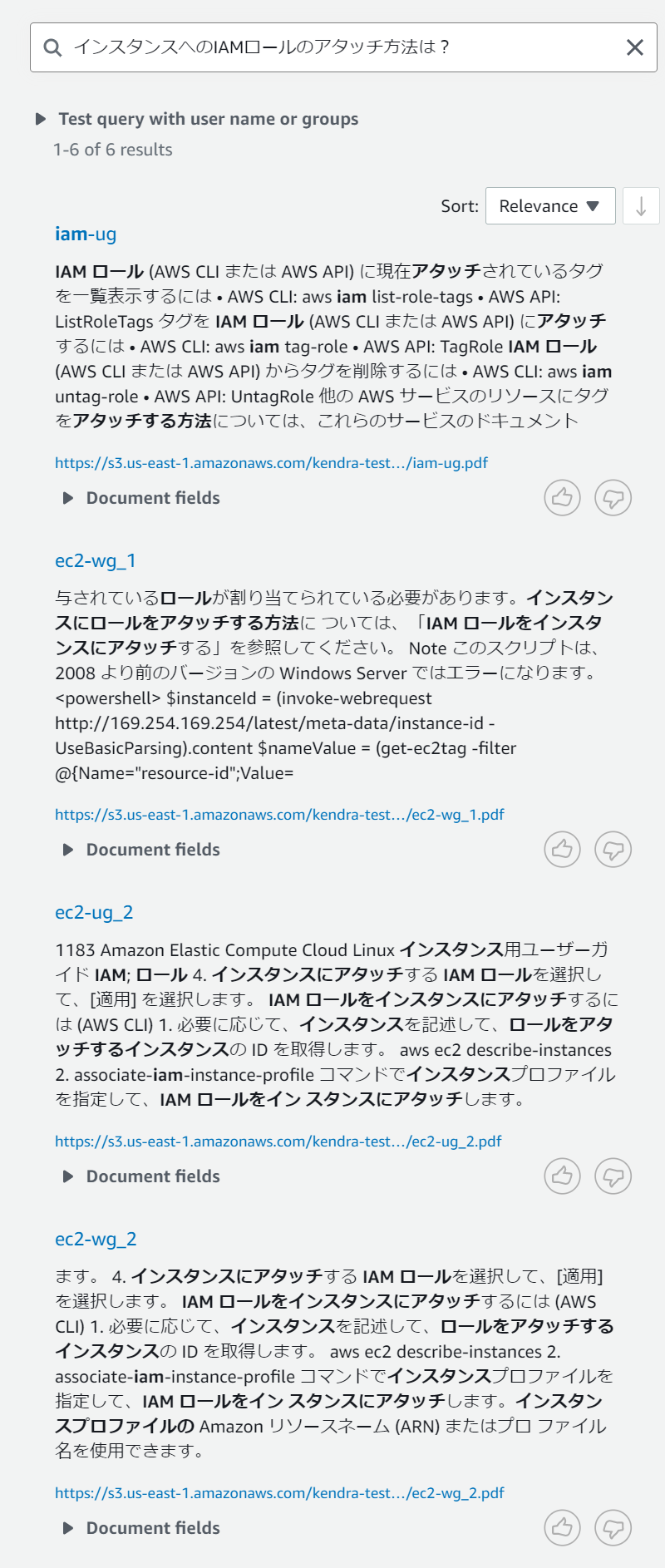
今回の結果では3番目、4番目の結果としてばっちりヒットした結果が表示されています。前回と比べてより具体的な単語での検索としたことが功を奏したのかもしれません。
1番目の検索結果はファイルのタイトルに一致する単語があるため、上位に出てしまっている可能性がありそうです。2番目は前の例と同じく文面的にはヒットしても仕方がない内容かもしれません。
3.3 検索例(3)
今度は同じ目的を違う粒度や書き方で検索して比べてみたいと思います。検索内容は①「AWSへのサインイン方法は?」、②「AWSマネジメントコンソールへのサインイン方法は?」、③「AWS Management Consoleへのサインイン方法は?」の3通りで試してみます。
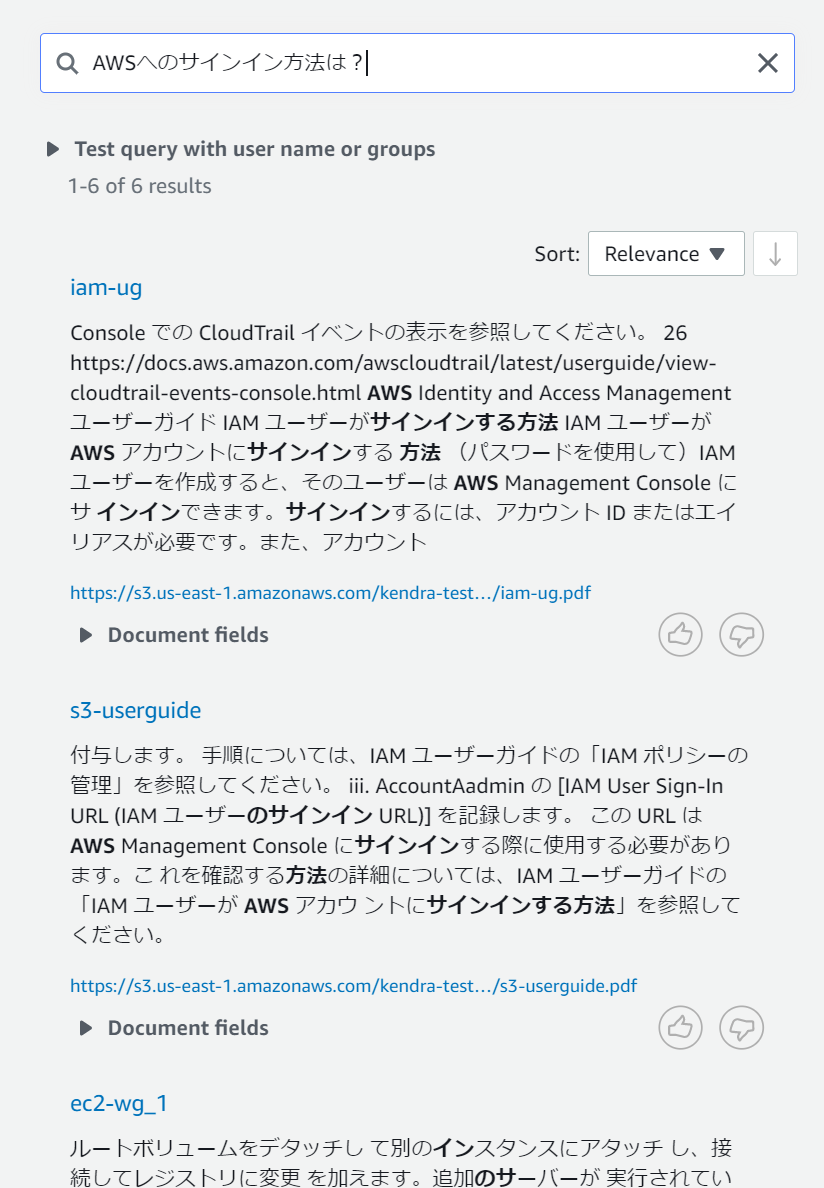
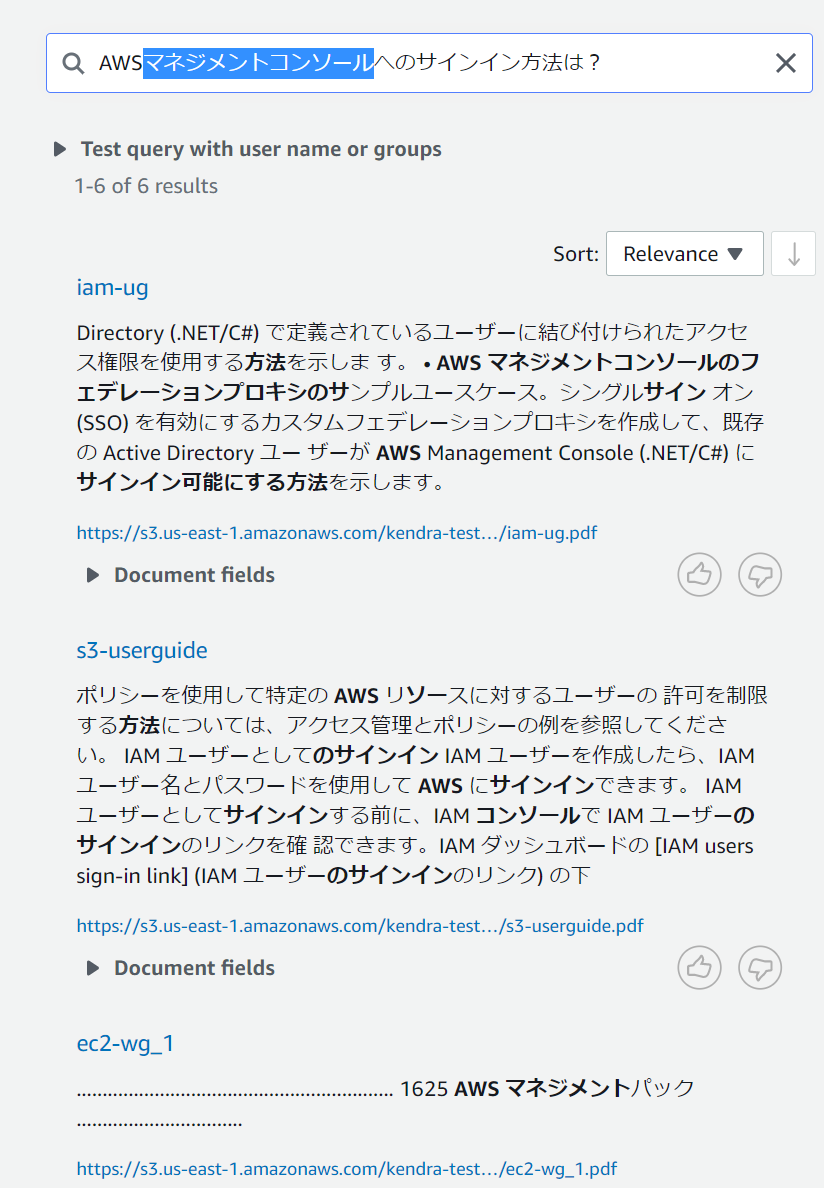
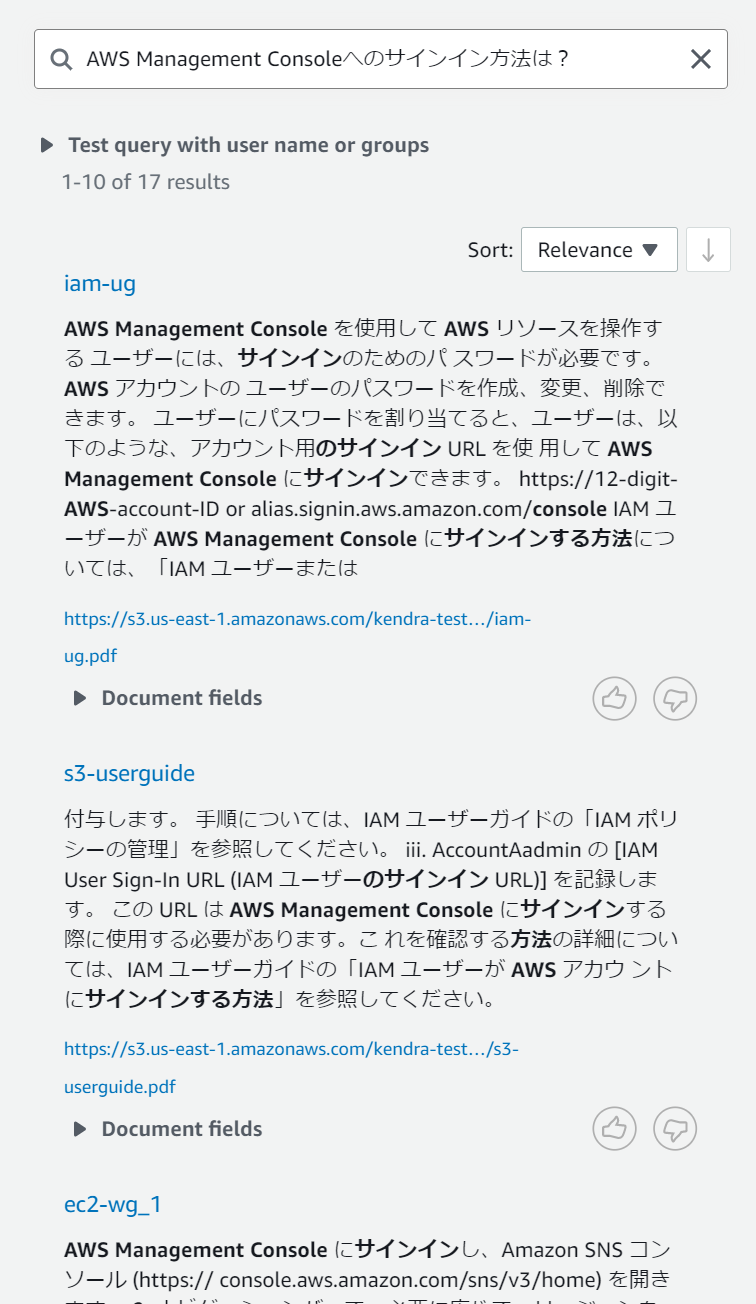
これらの結果を比べると以外にも①のみがばっちりと目的の場所を検索することができています。
②や③を見ると「AWSマネジメントコンソール」や「AWS Management Console」を含むほかの場所に引っ張られて違う場所がヒットしているように見受けられます。前回の検索例からより具体的な検索文にした方がいいのかと考えましたが、付け加えたワードが他の部分でより確からしいとそちらに引っ張られてしまうという弱点もあるようです。
また、②と③を比較すると同じ目的の言葉でもカタカナと英語といったように表記が異なると別物として判別されるようです。こういったものは類語辞書を手動で作成することで対応できるようですが、こちらの機能はまだ英語以外では未対応なようです。
3.4 検索速度
今回対象としたドキュメントはPDFで合計5000ページを超える大ボリュームなものになっています。ですが、今回試したすべての検索において数秒で応答が返ってきました。これだけの量のドキュメントからの検索と考えると非常に高速ではないでしょうか?
検索速度という観点で見ると単純なキーワード検索のサービスと比較しても非常に優秀な結果だと思います。
4.まとめ
ここまでAmazon Kendraの日本語の対応状況について確認してきました。その結果、現時点では日本語での検索精度については、もう一歩といわざるを得ないでしょうか。取り込んだドキュメントの書き方に合わせた検索文にする必要があり、表記ゆれ等に対応することもできていません。また、S3バケットに置いたPDFファイルで取り込んだ場合1ファイルにつき1検索結果しか出ないので1ファイル内にそれらしい箇所が複数あっても結果として出力されることがありません。そのため、章やページで分割して取り込むか別の方法で取り込む方がよさそうです。(今回の記事には含んでいませんが、Web Crawlerを使ってHTMLで記述されたWebページを取り込んだ場合はページごとに検索結果が1つずつヒットしました。)
一方、検索速度については非常に高速なので単純なキーワード検索として使用するだけでも利用価値はあるように思います。ただし、金額はそこそこお高いのでキーワード検索のためだけに利用するのは少しもったいないかもしれません。そのため、検索精度および追加機能(カスタム用語、結果のスコア付け等)が英語と同レベルまで充実してくることで非常に有用なサービスになりそうな予感がします。
さて、今回はいつもと趣向を変えてインフラ関連以外のサービスについて取り上げてみました。普段あまりアンテナを張れていない分野ですがAWSにはまだまだ有用なサービスがたくさんありますので、いろいろ試していきたいと思います。皆様もいろいろなサービスに触れてみると、今ある課題を解決できるものが見つかるかもしれません。
それではよいクラウドライフを!
当サイトの内容、テキスト、画像等の転載・転記・使用する場合は問い合わせよりご連絡下さい。
エバンジェリストによるコラムやIDグループからのお知らせなどを
メルマガでお届けしています。



