
関連するソリューション

業務改革
AI
グローバルイノベーションセンター
フェロー 黒住 好忠
みなさまこんにちは。フェローの黒住です。
近年の生成AIブームで、ChatGPTやGoogle Geminiなどのサービスでも利用されている大規模言語モデル(LLM: Large Language Model、以降はLLMと表記)が広く利用されるようになりました。LLMを利用すれば、
「人間の言葉」でAIとコミュニケーションが可能になる、非常に画期的な技術でした。
一方で、LLMにはまだ解決すべき課題がいくつか残っています。特に、独自の情報(例えば社内規約などの
パブリックに公開されていない情報)や最新の情報に基づいた回答には限界があります。
今回は、この課題を克服するために利用されることが増えたRAG(Retrieval-Augmented Generation:ラグと発音)について紹介したいと思います。
LLMの概要と課題
LLMはインターネットなど膨大な情報から学習し、人間の言葉(自然言語)を理解して生成するAIです。LLMは幅広い情報を学習しているため、文章の要約や質疑応答、翻訳等々、数多くの作業をこなすことができます。
しかし、LLMは「学習した情報に依存」しているため、学習していない情報については適切に答えることができません。例えば、インターネットには公開されていない「会社独自の社内規約」や、日々新しく出てくる
「最新の情報」などが、LLMが学習していない情報、つまりは、LLMが苦手としている情報になります。
LLMは学習していない情報は知り得ないため、例えばChatGPTに「入社4年目です。結婚祝い金について教えてください。」と聞いても、一般的な回答しか返ってきません。

LLMが知らない情報への対応
前述の通り、LLMには社内規定や新しい情報など「学習していない内容については答えられない」という課題がありました。最近では、この課題を解決するためにRAG(Retrieval Augmented Generation)というアプローチが採用されるようになりました。このRAGを利用すれば、これまでの限界を超えて「LLMに未知の情報について答えさせる」ことが可能になります。
例えばLLMに「社内の独自規定について回答させる」ことや、「最新のニュース記事について回答させる」ことなど、従来のLLMでは難しかったタスクがRAGによって実現可能になりました。
RAGのイメージ
RAGはLLMの限界を大きく広げるアプローチですが、その考え方はとてもシンプルです。
人間の世界に置き換えて例えるなら、RAGは「チートシート(日本だとカンニングシート)を渡して答えてもらう」ような手法です。つまり、情報を知らなくて答えられないのであれば、「回答に必要な情報も質問と一緒に渡せば答えられる」はず…という考え方です。
LLMは「文章の意味」は理解できるため、チートシートがあれば、その内容を読み取って質問に答えられるようになります。具体的には、下図のような感じで「回答するために必要な情報」を埋め込む形になります。(質問に対する回答も、規約の内容に沿った内容になっていることが確認できると思います)

RAGの仕組みと難しい点
RAGのポイントは、「質問に答えるための情報を一緒に渡す」点になりますが、実際の利用ケースにおいては
「どんな質問をされるか分からない」という課題があります。
例えば「有休について教えてください」という質問かもしれませんし、「総務部の連絡先を教えてください」という質問かもしれません。質問が異なれば、「回答に必要な情報」も異なるため、有休に関する質問に対しては
「有給休暇に関する規定の内容」、総務部の連絡先については「連絡先に関する情報」が必要になります。
LLMには「一度に質問できる文字数(厳密にはトークンサイズ)に制限」があるため、ありとあらゆる情報をチートシートで渡すことはできません。そのため、RAGを利用する場合は「質問内容に合わせて、回答に必要と思われる情報を決められた文字数に収まるように」入れ込む必要があります。
RAGの仕組みをもう少し細かく見ると、それぞれの頭文字が示すように、以下の3つのステップで処理が行われています。
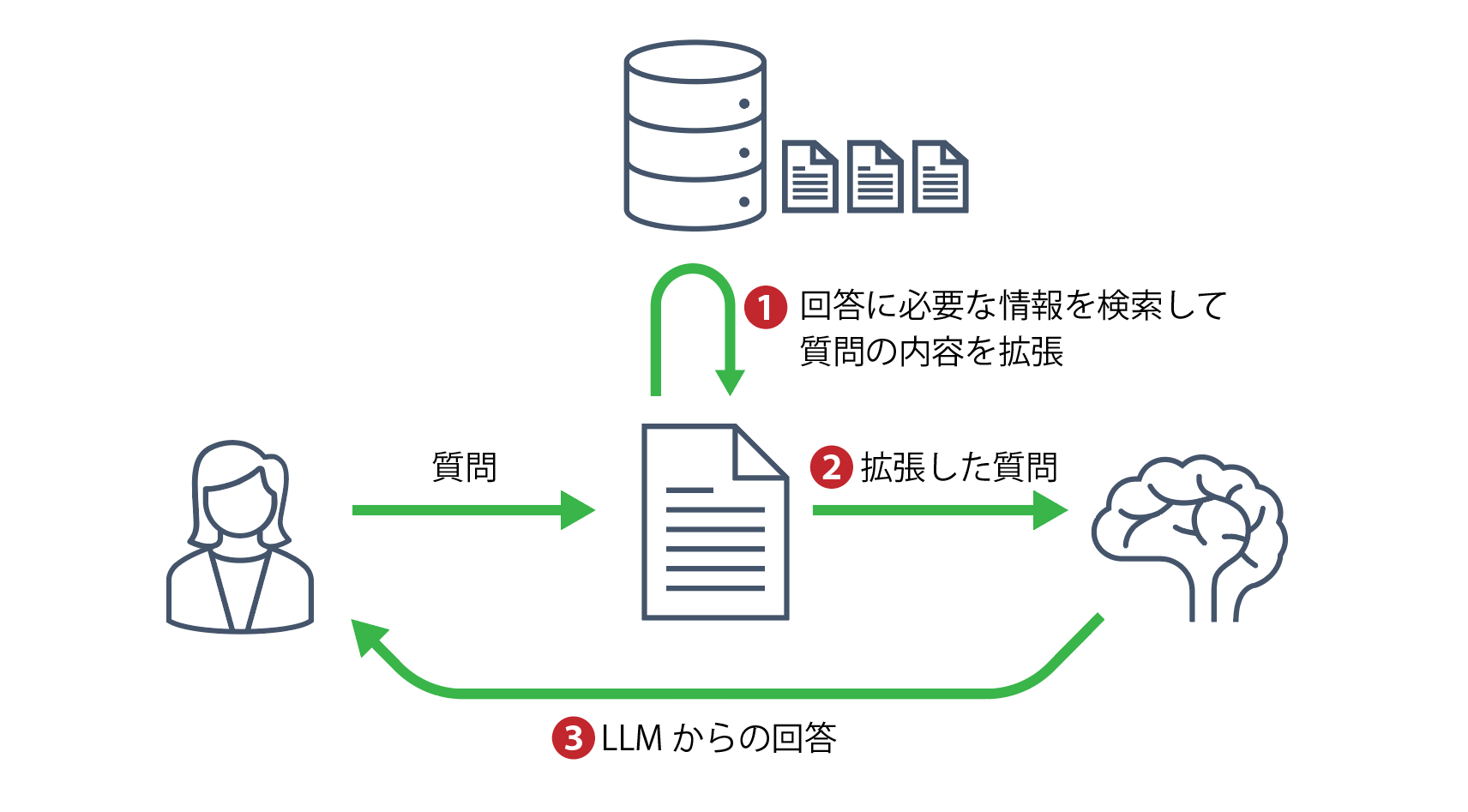
- Retrieval(検索):回答に必要な情報を見つけ出してくる部分
- Augument(拡張):質問に、上記で見つけ出した情報を付け加えて拡張する部分
- Generation(生成):拡張した内容に対して答えを生成する部分
RAGの考え方自体は簡単なのですが、実際にRAGを利用する上では、Retrieval、つまり「回答に必要な情報を見つけ出してくる」部分が最も難しい部分であり、さまざまなノウハウが要求される部分でもあります。
適切な情報を見つけるために、文章自体を数値化(多次元のベクトル情報に変換)し、情報の関係性をコサイン類似度などで比較して…というような処理を行うケースが多いのですが、この部分はAIに関する知識が必要不可欠になります。
また、単純にこれらの技術を使うだけでは正しい情報が「取得できない」ことも多く、実際には複数のアプローチを組み合わせて対応することになります。
誤って見当違いな情報を取得してきた場合、LLMは誤った解答を返すなど、質問に対する適切な回答が行えません。そのため、RAGの中でも「必要な情報を見つけ出してくる部分」は非常に重要な処理となります。
簡単に利用できるID AIコンシェルジュ Pro
社内規定など、独自の情報に基づいた回答はRAGを使って実現できるのですが、実際に「適切に機能する」RAGの仕組みを作るためには、高度な知識や、さまざまなノウハウが要求されます。難しいことは考えずに、「データさえ用意すれば、LLMが回答できるようにしてほしい」という声も多くいただいているため、弊社では「データを用意するだけ」で、LLMがその情報に基づいて回答できるサービスを
「ID AI コンシェルジュ Pro」として開発しました。

ID AI コンシェルジュ Proでは、RAGの仕組みを独自に組み込んでいるため、社内規定などのデータを用意いただくだけで、簡単にご利用いただけるサービスになっています。
ID AIコンシェルジュ Proの利用イメージ
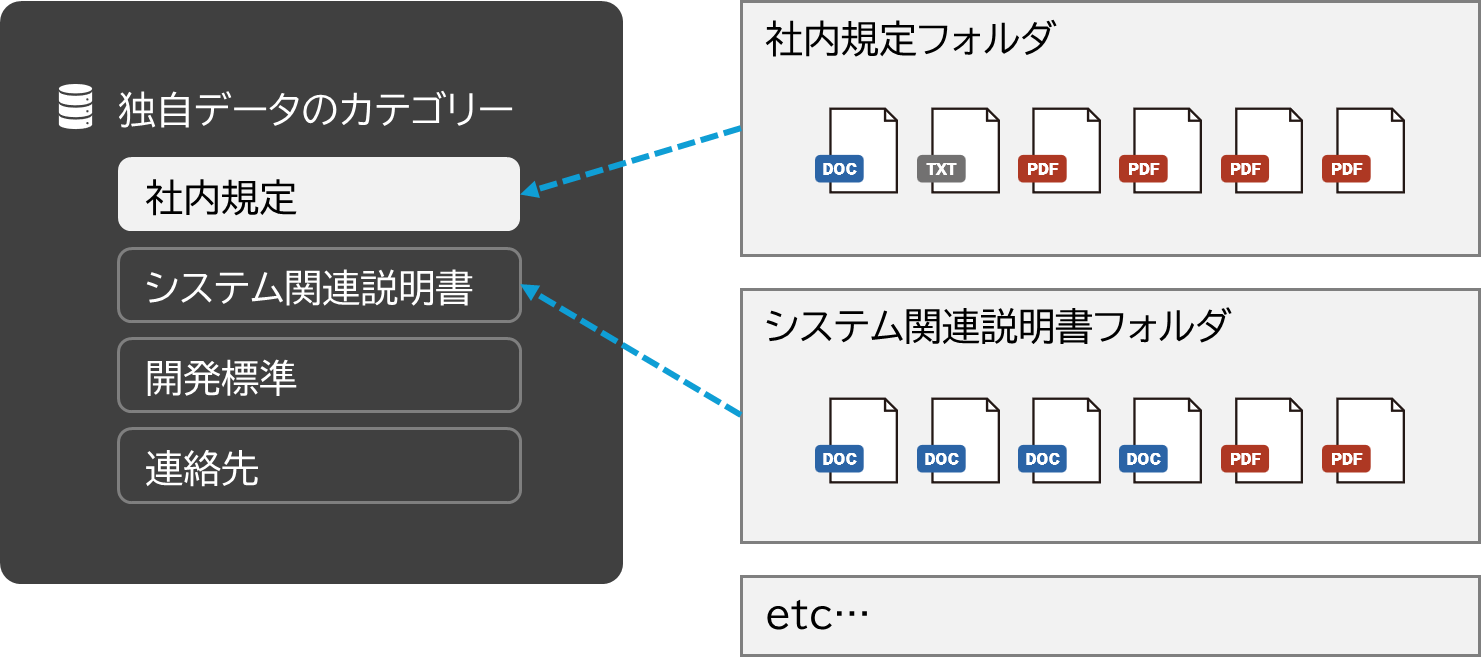
「社内規定」を例にご紹介します。
コンシェルジュ Proでは、独自データをフォルダに分けて管理することができます。例えば、社内規定や、システムに関する取扱説明書、連絡先の情報など、目的や役割に応じてカテゴリを分けることが可能です。
利用時は、「回答してほしいカテゴリを選択して質問」だけで、対象フォルダ内にある情報に基づいて回答が行われます。また、各フォルダ単位にユーザの参照権限設定が行えるため、例えば「人事部の人たちにだけ情報を見せる」というような制御も可能になります。
例えば、「社内規定」を選択して「結婚しました。祝い金について教えてください。」と質問すると、社内規定フォルダ内のファイルを自動で探し出して、該当する規定を元に回答が返ってきます。
LLMは、時々「嘘の内容を回答する」事象(ハルシネーション)が発生するのですが、コンシェルジュ Proを利用すれば、「回答に利用した情報源」も表示するため、回答のエビデンス情報も明確に確認できます。

※この規定はデモ用に作成した架空の規定情報になります。
まとめ
今回は、現在のAI技術の中でも特に注目されている大規模言語モデル(LLM)の可能性と限界、そしてこれらの限界を克服するためのRetrieval-Augmented Generation(RAG)についてご紹介しました。LLMが提供する「人間の言葉を理解し、新しい文章を生成する能力」は、情報の要約、質疑応答や翻訳など、さまざまな用途で活用できます。しかし、社内規定や最新情報など、LLMが学習していない「独自の情報に対する回答」には大きな課題がありました。
RAGのアプローチを導入することで、これらの課題の解決策が見えてきました。RAGは、LLMに対して「必要な情報を検索して追加する」という新たな能力を追加することができ、未知の情報に対する回答性能を大きく向上させることが可能です。これにより、企業が持つ独自のデータなどに基づく質問に対しても、より正確に答えることが可能になります。
弊社の「ID AI コンシェルジュ Pro」は、RAGの技術を活用し、企業が直面するこれらの課題を解決できるサービスを提供します。データを用意するだけで独自情報に基づいた回答が可能になるため、実際のビジネスにおいて、迅速で簡単にサービスの導入が可能になります。
AIの技術は日々進化しており、私たちの生活やビジネスに新たな可能性をもたらし続けています。我々の提供する「ID AI コンシェルジュ Pro」が、皆さまのビジネスに新しい価値を提供できることを心より願っております。興味を持たれた方は、ぜひ「ID AI コンシェルジュ」のページからお問い合わせください。
それではまた、次回のコラムでお会いしましょう。
リンク集
今回の記事に関連するリンクを以下に記載しております。- 技術情報(外部サイト)
- ID AI コンシェルジュに関する情報(弊社サイト)
当サイトの内容、テキスト、画像等の転載・転記・使用する場合は問い合わせよりご連絡下さい。
エンジニアによるコラムやIDグループからのお知らせなどを
メルマガでお届けしています。
