
関連するソリューション

業務改革
AI
エバンジェリスト・フェロー 玉越 元啓 
今回は、「スクレイピング」をテーマでお送りします。過去の記事で何回かスクレイピングを利用した情報収集をしていたところ、具体的に解説してほしいとのリクエストをいただきましたので、応えていきたいと思います。
- スクレイピングとは
- 今スクレイピングが注目されている理由
- Excel
- VBA
- 【参考】IEのサポート期限切れに対する対応>
- Python
- スクレイピング実行時の注意
- >最後に
スクレイピングとは
ウェブスクレイピングを指しており、wwwから自動的に情報を集める方法です。ここでは、wikiの説明を引用しておきます。
『ウェブスクレイピングとは、ウェブサイトから情報を抽出するコンピュータソフトウェア技術のこと。通常このようなソフトウェアプログラムは低レベルのHTTPを実装することで、もしくはウェブブラウザを埋め込むことによって、WWWのコンテンツを取得する。ウェブスクレイピングはユーザーが手動で行なうこともできるが、一般的にはボットやクローラを利用した自動化プロセスを指す。』
引用:ウェブスクレイピング(Wikipedia)
『ウェブスクレイピングとは、ウェブサイトから情報を抽出するコンピュータソフトウェア技術のこと。通常このようなソフトウェアプログラムは低レベルのHTTPを実装することで、もしくはウェブブラウザを埋め込むことによって、WWWのコンテンツを取得する。ウェブスクレイピングはユーザーが手動で行なうこともできるが、一般的にはボットやクローラを利用した自動化プロセスを指す。』
引用:ウェブスクレイピング(Wikipedia)
今スクレイピングが注目されている理由
AIの利用が身近になってきた半面、分析・学習のためのデータを自分で集める必要があることも増えてきました。他、人が毎回Webの情報を収集して記録するのは意外と手間がかかるものです。
RPAでも同様のことが出来ますが、取得した情報の記録や編集にはExcelなどの外部のアプリケーションに頼ることになり、また、webページの見た目の変更などで動かなくなりがちです。そこで実務においては、RPAは複数のアプリケーションを動かすためのワークフロー的な役割につかい、スクレイピング処理はアプリケーションに任せる(例えばはExcelのマクロなど)ことで、自動化されたプロセスの修正範囲を限定的にする運用がよくされています。
私も、スクレイピングはPythonで行い、全体の処理を順番に実行するのはAutomatorというMacの標準ツールで行っています。
RPAでも同様のことが出来ますが、取得した情報の記録や編集にはExcelなどの外部のアプリケーションに頼ることになり、また、webページの見た目の変更などで動かなくなりがちです。そこで実務においては、RPAは複数のアプリケーションを動かすためのワークフロー的な役割につかい、スクレイピング処理はアプリケーションに任せる(例えばはExcelのマクロなど)ことで、自動化されたプロセスの修正範囲を限定的にする運用がよくされています。
私も、スクレイピングはPythonで行い、全体の処理を順番に実行するのはAutomatorというMacの標準ツールで行っています。
Excel
Excelのパワークエリ―という機能を用いてスクレイピングが可能です。2016年に公開されたMicrosoft製のデータ分析用Excelアドインであり、Excel2010以降に対応しています。2016以降は標準で搭載されていますが、それ以前のバージョンの場合は、以下のサイトから入手できます。
マイクロソフト ダウンロードセンター/Microsoft Power Query for Excel(外部サイト)
今回の確認は、Excel 2016で行っています。
マイクロソフト ダウンロードセンター/Microsoft Power Query for Excel(外部サイト)
今回の確認は、Excel 2016で行っています。
1.「データ」タブの「新しいクエリ」を選択します。
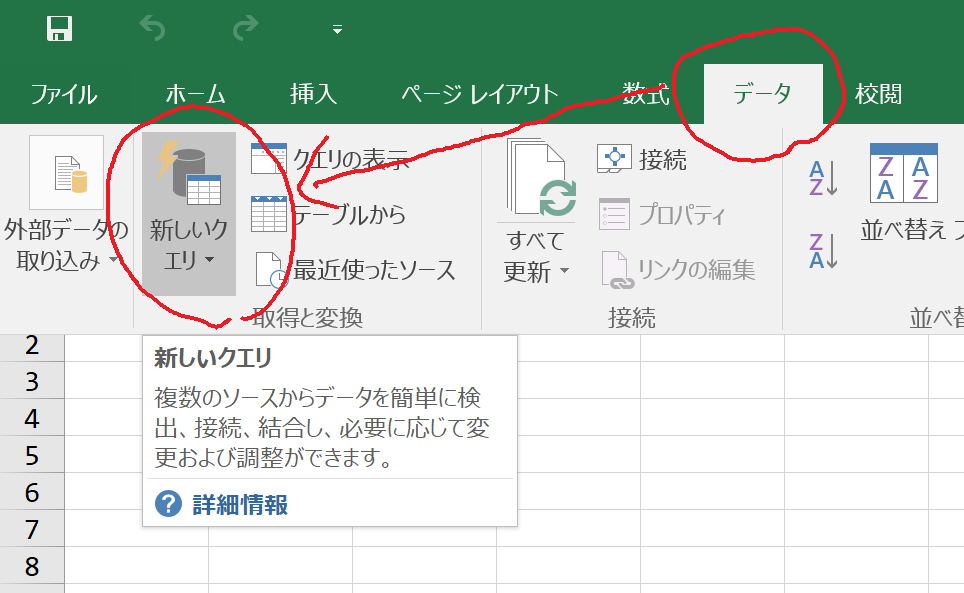
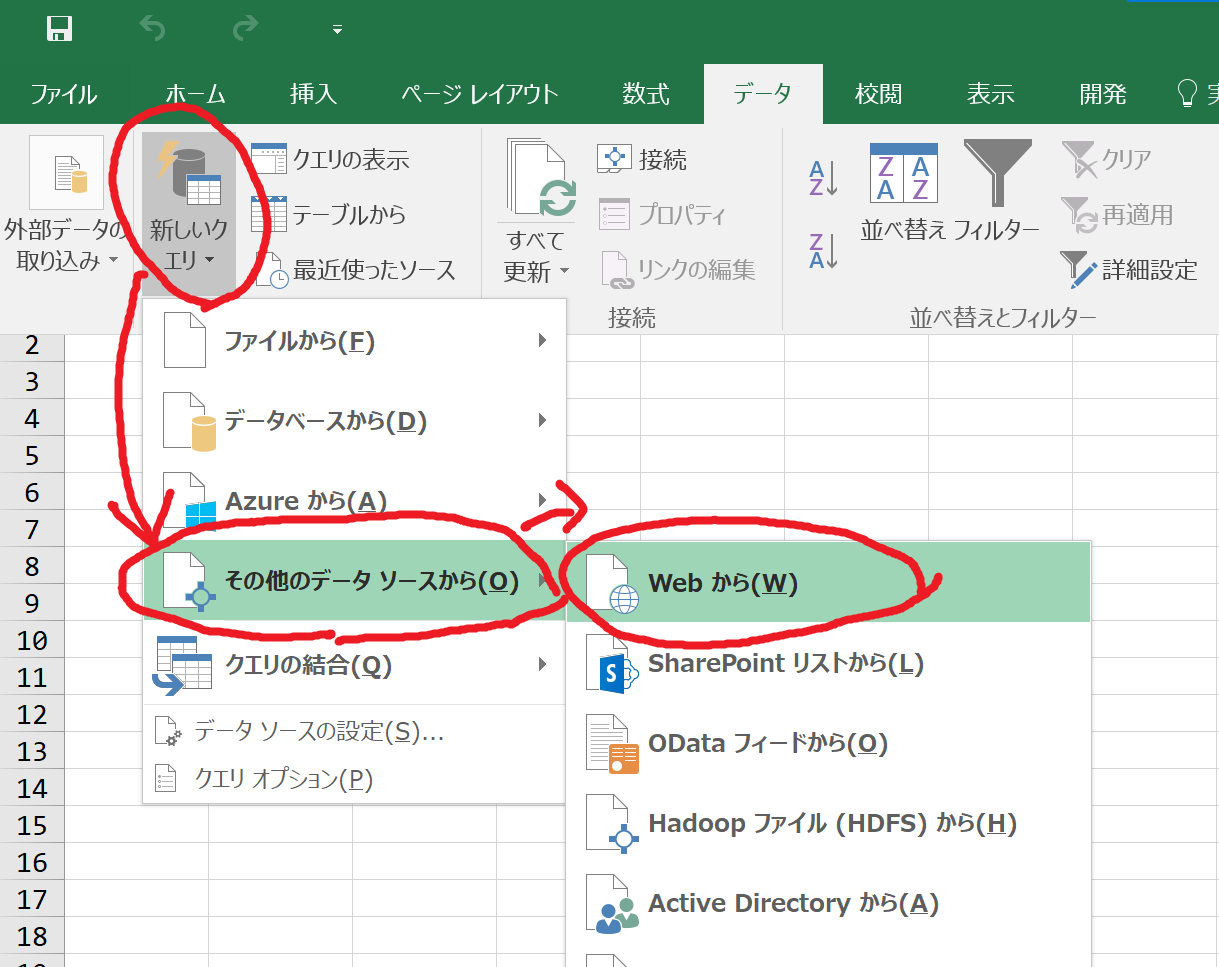
2.「その他のデータソースから」をクリックすると表示される「Webから」を選択します。
3.取得したい情報が公開されているURLを入力し、OKをクリックします。
今回は機能の確認として、テーブルがある筆者のコラムのURL(https://www.idnet.co.jp/column/page_224.html)を指定しました。
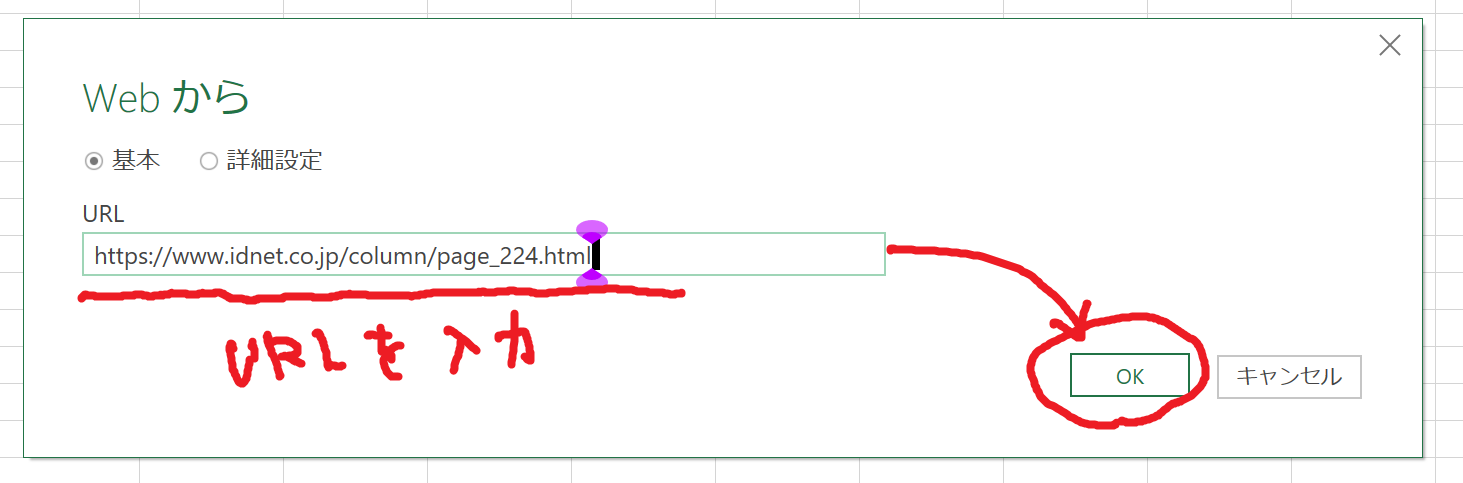
今回は機能の確認として、テーブルがある筆者のコラムのURL(https://www.idnet.co.jp/column/page_224.html)を指定しました。
4.ナビゲーター画面が開き、3で指定したURLから情報が取得されます。
指定するページの情報量や環境によっては、数秒ほど読み込みまで時間がかかります。取得が終わると、左側に取得可能な情報のまとまりが表示されます。ここではTable 0を選択しました。右側のテーブルビューに、取得できる情報が表示されるので、間違いがないか確認して、読み込みをクリックします。
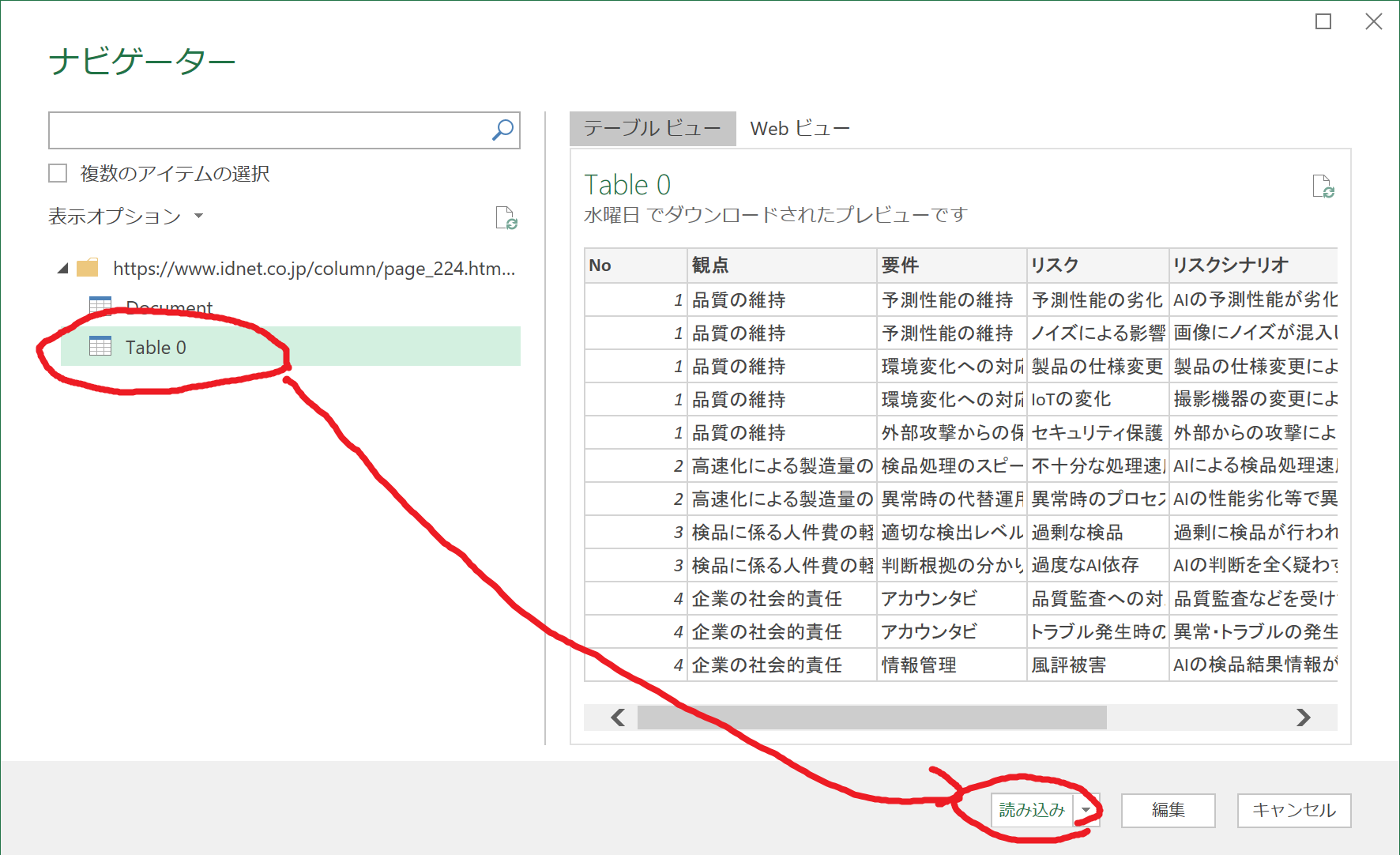
指定するページの情報量や環境によっては、数秒ほど読み込みまで時間がかかります。取得が終わると、左側に取得可能な情報のまとまりが表示されます。ここではTable 0を選択しました。右側のテーブルビューに、取得できる情報が表示されるので、間違いがないか確認して、読み込みをクリックします。
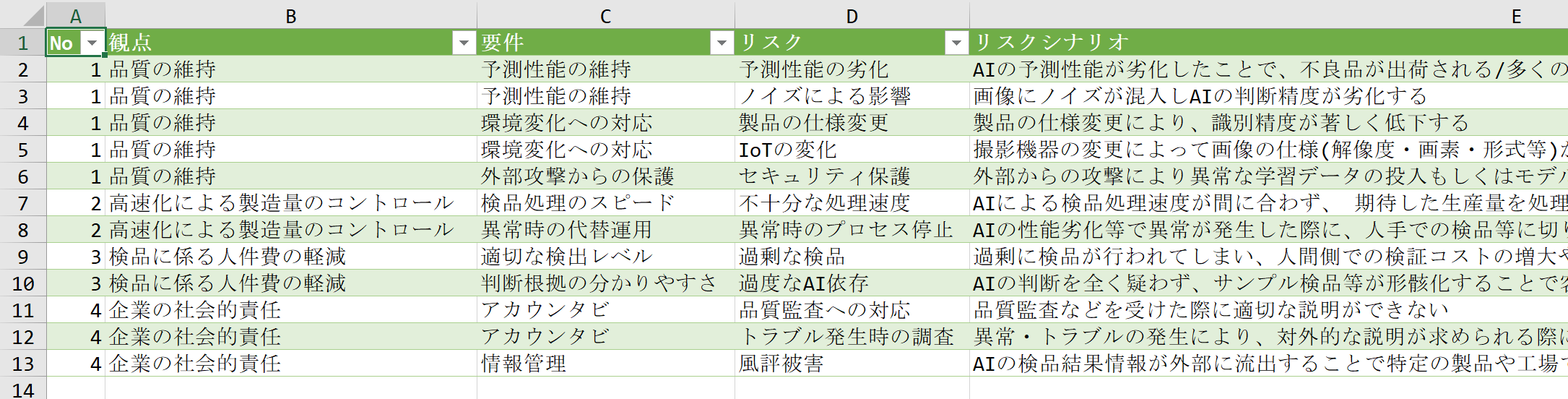
5.シートにWebの情報が表示されます。
このままでは、コピーしてペーストするのと大差ありません。パワークエリ―を使う利点については次で解説します。
このままでは、コピーしてペーストするのと大差ありません。パワークエリ―を使う利点については次で解説します。
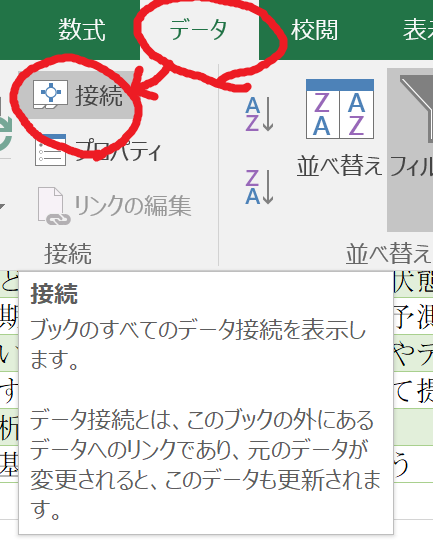
6.取得した情報を最新化する設定
データタブの接続を選択
データタブの接続を選択
先ほど作成したパワークエリ―を選択し、プロパティを表示します。
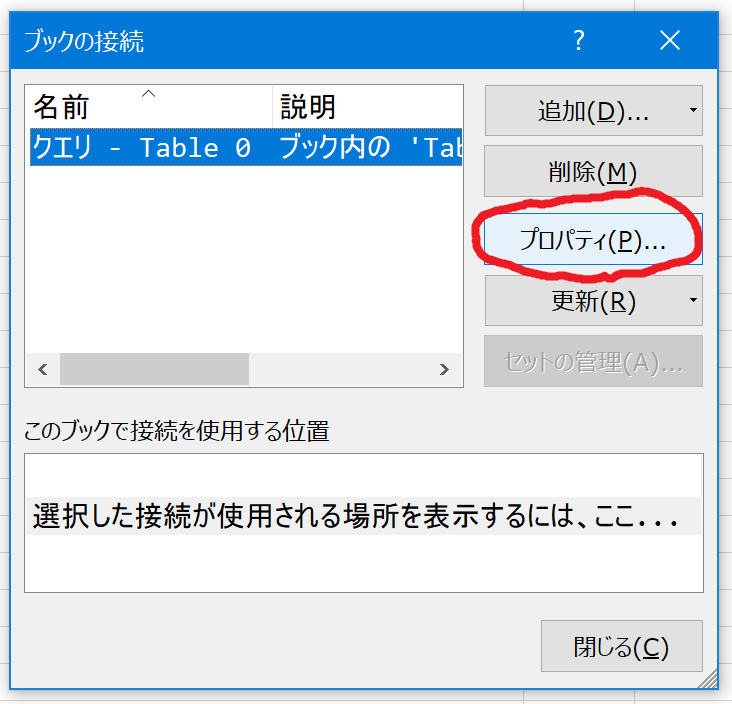
情報を取得したいサイクルに合わせて設定を変更します。
「定期的に更新する」にチェックをいれて60分、とするとファイルを開いてから60分ごとに情報が更新されるようになります。毎日1回更新すればよいのであれば、ファイルを開くときにデータを更新する、にチェックをいれてOKをクリックします。
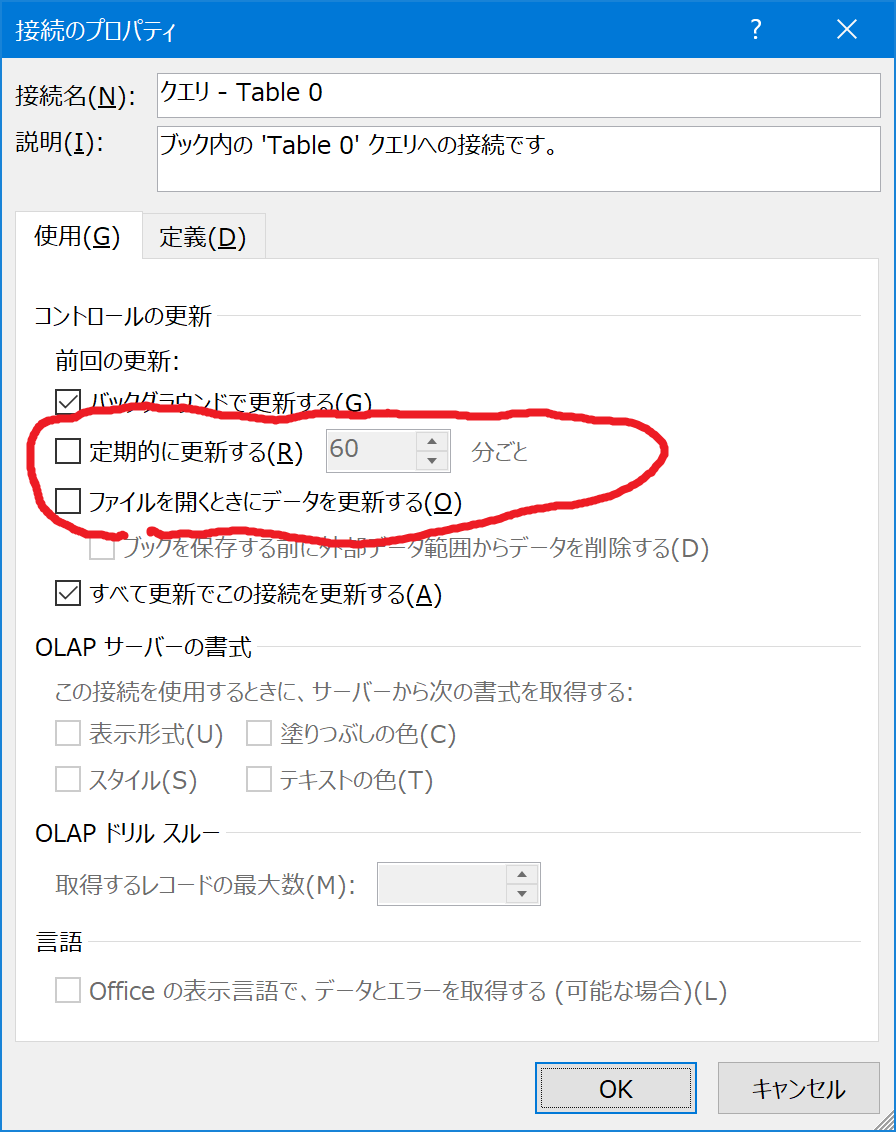
「定期的に更新する」にチェックをいれて60分、とするとファイルを開いてから60分ごとに情報が更新されるようになります。毎日1回更新すればよいのであれば、ファイルを開くときにデータを更新する、にチェックをいれてOKをクリックします。
これで、WEBの情報を定期的に取得してデータを最新化するExcelブックの完成です。
VBA
VBAによる(この後のPythonも)スクレイピングの利点は、取得する情報の自由度が高いことにあります。
1.マクロのエディタ画面(仮)から、参照設定を開き、次の2つのライブラリにチェックを入れ、参照可能にします。
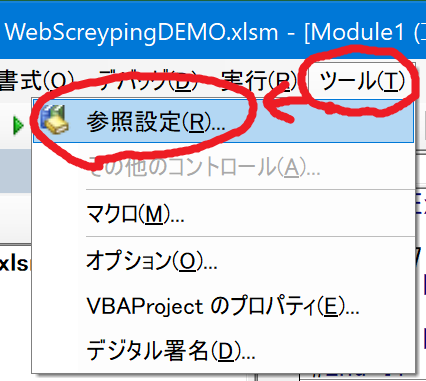
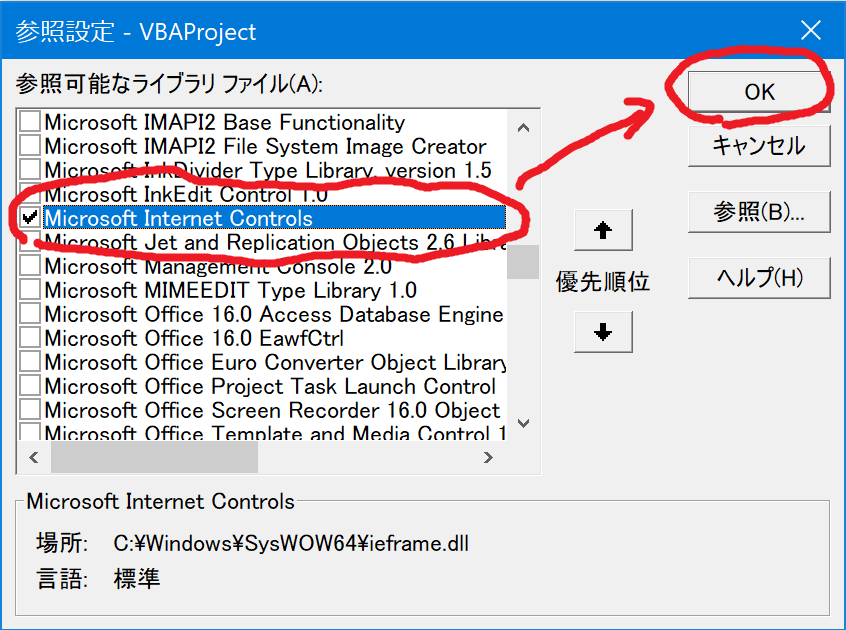
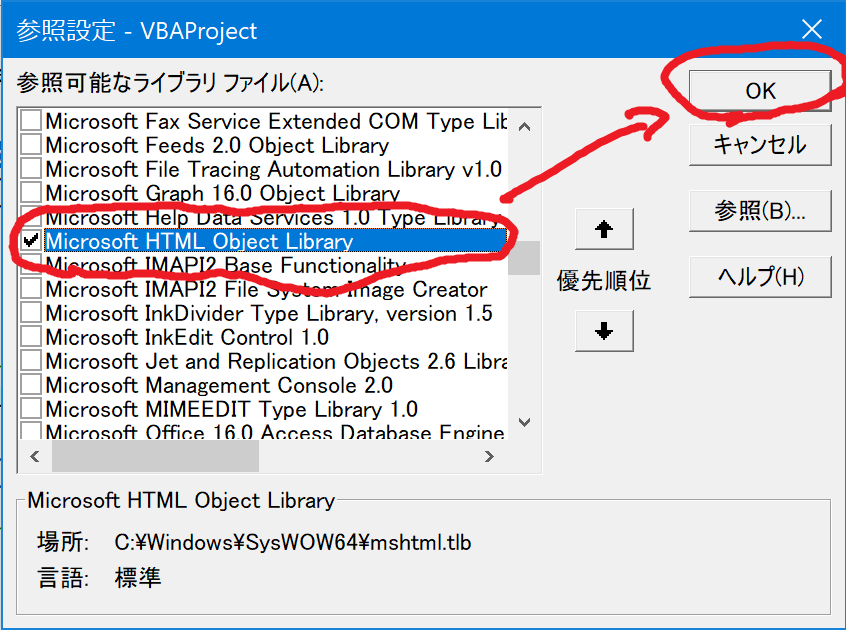
1.マクロのエディタ画面(仮)から、参照設定を開き、次の2つのライブラリにチェックを入れ、参照可能にします。
- Microsoft Internet Controls
- Microsoft HTML Object Library
2.スクレイピングのサンプルコード
<ソースコード>
<ソースコード>
Sub WebScrapingDEMO()Dim ie As New InternetExplorerDim html As New HTMLDocumentDim tables As IHTMLElementCollectionDim table As HTMLTableDim hrow As HTMLTableRowDim hcell As HTMLTableCellDim MyCollection As New CollectionDim URL As StringDim nR, nC As LongURL = "https://www.idnet.co.jp/column/page_174.html"ie.Visible = Falseie.navigate URLRem Html読み込みまで待機DoDoEventsLoop Until ie.readyState = READYSTATE_COMPLETE '=4Set html = ie.documentSet tables = html.getElementsByTagName("table")nR = 0For Each table In tablesFor Each hrow In table.RowsnR = nR + 1nC = 0For Each hcell In hrow.CellsnC = nC + 1Cells(nR, nC).Value = hcell.innerTextNextNextNextMsgBox "Done!"End Subポイント解説
Dim ie As New InternetExplorer
Internet Explorer をCOMオブジェクトとしてインスタンス化(起動)します。この "ie" でWebの操作を行っていくことになります。
ie.navigate URL
これで指定したURLに遷移し、
DoDoEventsLoop Until ie.readyState = READYSTATE_COMPLETE '=4
ページの読み込みまで待機します。
Set tables = html.getElementsByTagName("table")
ページ内のテーブルタグの情報を抽出しています。HTMLのテーブル内の情報が行単位で記述されています。この後のループの中で、1行ずつ読み込み、各行のセル内の情報を順番に取得してシートに転記しています。
改良のポイント
HTMLDocument(ソース内では変数html)は、HTMLの情報を取得するためのメソッドが幾つか用意されています。例えば他のtagや特定のclass名をもつタグ内の情報を取得することができます。下では特定のクラスが指定されている情報を取得しています。
Set tables = html.getElementsByClassName("sampleClassNamse").Item
実行結果サンプル

【参考】IEのサポート期限切れに対する対応
Microsoft Internet Controlsは、Internet Explorerの操作を通してWEBアクセスするために用意されていたライブラリですので、IEのサポート切れに伴い今後の運用について懸念していましたが、2022年5月に、こちらのライブラリのサポートは継続されるこが表明されました。詳細は下の発表資料をご覧ください。
Internet Explorer 11 desktop app retirement FAQ(外部サイト)
原文
"I ran into issues with my application which utilizes IE through automation. Will this be fixed? (Updated: May 25, 2022)
These IE COM objects have been restored to their original functionality as of the Windows 11 November 2021 "C" update and the Windows 10 February 2022 "B" update (for versions 1809 and later). The COM scenarios will also continue to work after the IE11 desktop application is disabled after June 15, 2022. "
抄訳
IE COMオブジェクトは、Windows11の2021年11月の「C」更新プログラムおよびWindows10の2022年2月の「B」更新プログラム (バージョン 1809 以降) の時点で、元の機能に復元されました。COM シナリオは、IE11 デスクトップ アプリケーションが 2022年 6月15日以降に無効になった後も引き続き機能します。
Internet Explorer 11 desktop app retirement FAQ(外部サイト)
原文
"I ran into issues with my application which utilizes IE through automation. Will this be fixed? (Updated: May 25, 2022)
These IE COM objects have been restored to their original functionality as of the Windows 11 November 2021 "C" update and the Windows 10 February 2022 "B" update (for versions 1809 and later). The COM scenarios will also continue to work after the IE11 desktop application is disabled after June 15, 2022. "
抄訳
IE COMオブジェクトは、Windows11の2021年11月の「C」更新プログラムおよびWindows10の2022年2月の「B」更新プログラム (バージョン 1809 以降) の時点で、元の機能に復元されました。COM シナリオは、IE11 デスクトップ アプリケーションが 2022年 6月15日以降に無効になった後も引き続き機能します。
■Python
VBAよりも取得・操作できる情報の自由度が高まります。一方、取得した情報の取り扱いには注意が必要です。この点については後述します。
1.対象ページの分析
今回は弊社コラムのテーマ一覧を作成してみたいと思います。コラムのページを開いてみると、テーマは「2022年度の人工知能学会からみるAIトレンド ~今後の活用の可能性~」とあります。
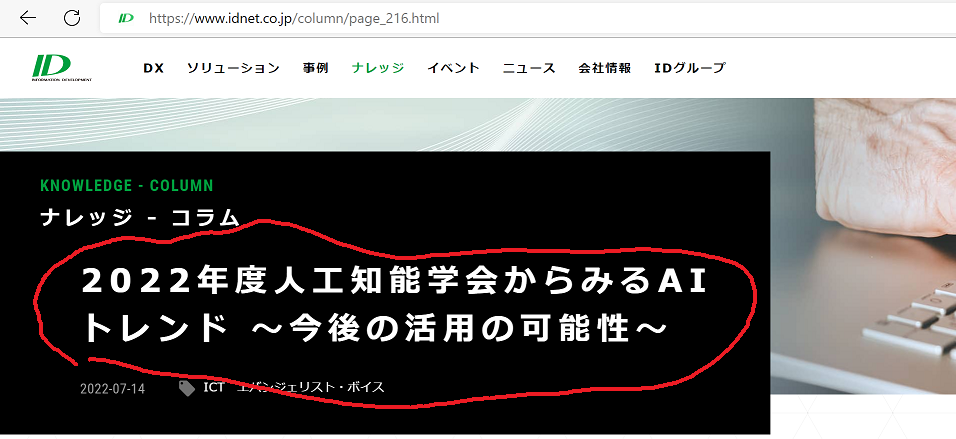
2022年度人工知能学会からみるAIトレンド ~今後の活用の可能性~
ページのHTMLソースをみてみます。
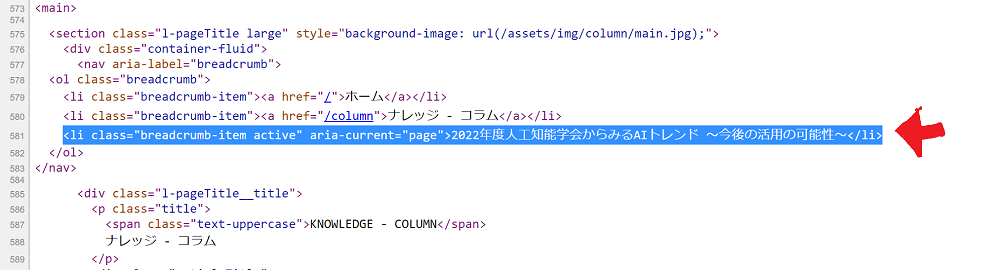
テーマは、
<li class="breadcrumb-item active" aria-current="page">2022年度人工知能学会からみるAIトレンド ~今後の活用の可能性~に記載されているので、liタグのうち、classが "breadcrumb-item active" の内容を抽出すればよさそうです。
今回は弊社コラムのテーマ一覧を作成してみたいと思います。コラムのページを開いてみると、テーマは「2022年度の人工知能学会からみるAIトレンド ~今後の活用の可能性~」とあります。
2022年度人工知能学会からみるAIトレンド ~今後の活用の可能性~
ページのHTMLソースをみてみます。
テーマは、
<li class="breadcrumb-item active" aria-current="page">2022年度人工知能学会からみるAIトレンド ~今後の活用の可能性~に記載されているので、liタグのうち、classが "breadcrumb-item active" の内容を抽出すればよさそうです。
2.ソース
import timeimport requestsfrom bs4 import BeautifulSoupurllists =["https://www.idnet.co.jp/column/page_232.html","https://www.idnet.co.jp/column/page_198.html","https://www.idnet.co.jp/column/page_224.html"]for url in urllists:print(url)response = requests.get(url)html_doc = response.textsoup = BeautifulSoup(html_doc, 'html.parser')titles = []real_title_tags = soup.find_all('li',{'class':'breadcrumb-item active'})for tag in real_title_tags:titles.append(tag.text)print(titles)time.sleep(10)
3.実行結果
https://www.idnet.co.jp/column/page_232.html
['今さら聞けないコンテナ管理の新常識\u3000「Kubernetes(k8s)/OpenShift」']
https://www.idnet.co.jp/column/page_198.html
['技術発展に避けて通れないAIの「標準化」とは?']
https://www.idnet.co.jp/column/page_224.html
['2022年度人工知能学会からみるAIトレンド ~今後の活用の可能性~']
https://www.idnet.co.jp/column/page_232.html
['今さら聞けないコンテナ管理の新常識\u3000「Kubernetes(k8s)/OpenShift」']
https://www.idnet.co.jp/column/page_198.html
['技術発展に避けて通れないAIの「標準化」とは?']
https://www.idnet.co.jp/column/page_224.html
['2022年度人工知能学会からみるAIトレンド ~今後の活用の可能性~']
4.解説
まずは、使用しているライブラリについてです。
まずは、使用しているライブラリについてです。
import timeimport requestsfrom bs4 import BeautifulSoup
"time"は、ウェブアクセス時に負荷をかけないよう時間調整するために利用しています。
"requests"は、pythonでウェブアクセスを行うためのライブラリです。
https://pypi.org/project/requests/
"bs4"
Beautiful Soupは、Webページから簡単に情報をスクレイピングできるライブラリです。HTMLまたはXMLパーサーの上に位置し、解析、検索、変更等ができる関数が提供されています。Pythonでスクレイピングを行う方法はいくつかありますが、個人的に一番簡単だと感じたBeautifilSoupを使っています。
https://pypi.org/project/beautifulsoup4/
"requests"は、pythonでウェブアクセスを行うためのライブラリです。
https://pypi.org/project/requests/
"bs4"
Beautiful Soupは、Webページから簡単に情報をスクレイピングできるライブラリです。HTMLまたはXMLパーサーの上に位置し、解析、検索、変更等ができる関数が提供されています。Pythonでスクレイピングを行う方法はいくつかありますが、個人的に一番簡単だと感じたBeautifilSoupを使っています。
https://pypi.org/project/beautifulsoup4/
urllists =["https://www.idnet.co.jp/column/page_232.html",(略)
情報を取得したいウェブページをリスト化しています。連番で作成されるのであれば、自動生成してもよいでしょう。
response = requests.get(url)html_doc = response.text
指定したURLにHTTPのGETリクエストを送り、HTMLソースを抜き出します。
soup = BeautifulSoup(html_doc, 'html.parser')
BeautifulSoupでHTMLソースを解析します。
real_title_tags = soup.find_all('li',{'class':'breadcrumb-item active'})
解析結果をもとに、liタグのうち、classが "breadcrumb-item active" の内容を抽出します。
いかがだったでしょうか。非常にシンプルなコードでスクレイピングできることを実感いただけたのではないでしょうか。
実運用する際には、HTTPリクエストのエラー処理や会員ページなどWEBアクセスする際に認証が必要な場合の処理を追加していくことになります。
いかがだったでしょうか。非常にシンプルなコードでスクレイピングできることを実感いただけたのではないでしょうか。
実運用する際には、HTTPリクエストのエラー処理や会員ページなどWEBアクセスする際に認証が必要な場合の処理を追加していくことになります。
スクレイピング実行時の注意
スクレイピングする際、特に下の3点について気を付ける必要があります。
- 高負荷
- Webサイトの規約
- 著作権
1.高負荷
自動で処理できる反面、短時間かつ高頻度でウェブサイトにアクセスすることで、当該サイトのサーバやネットワークに高い負荷をかけることになります。
2.Webサイトの規約
Webサイトによっては、規約に同意することで情報を公開しているものもあります。規約の中でスクレイピングを禁止しているサイトも存在します。利用前に該当サイトを利用するための条件を確認しましょう。
3.著作権
サイトの情報は著作物でもあります。スクレイピングにおける課題について解説している法律事務所がありましたので、紹介します。
参考サイト
スクレイピングとは?注目を集める便利なデータ収集方法の法的課題を解説(外部サイト)
スクレイピングは違法?3つの法律問題と対応策を弁護士が5分で解説(外部サイト)
自動で処理できる反面、短時間かつ高頻度でウェブサイトにアクセスすることで、当該サイトのサーバやネットワークに高い負荷をかけることになります。
2.Webサイトの規約
Webサイトによっては、規約に同意することで情報を公開しているものもあります。規約の中でスクレイピングを禁止しているサイトも存在します。利用前に該当サイトを利用するための条件を確認しましょう。
3.著作権
サイトの情報は著作物でもあります。スクレイピングにおける課題について解説している法律事務所がありましたので、紹介します。
参考サイト
スクレイピングとは?注目を集める便利なデータ収集方法の法的課題を解説(外部サイト)
スクレイピングは違法?3つの法律問題と対応策を弁護士が5分で解説(外部サイト)
最後に
スクレイピングの利点や実現方法について解説いたしました。注意点をよくご理解いただき、実践してみてください。「スクレイピングを組み込んだワークフローをつくって業務のDX推進したい」などのご相談にもお応えできます。近くのIDグループ社員にお声がけいただくか、下の窓口までご連絡ください。
ソリューションに関するお問い合わせ
ソリューションに関するお問い合わせ
当サイトの内容、テキスト、画像等の転載・転記・使用する場合は問い合わせよりご連絡下さい。
エバンジェリストによるコラムやIDグループからのお知らせなどを
メルマガでお届けしています。



