
関連するソリューション

アプリケーション開発
マネージドサービス(運用・保守)
セキュリティ製品
業務改革
グローバル・イノベーション・センター
エバンジェリスト 黒住 好忠
こんにちは。グローバルイノベーションセンター、エバンジェリストの黒住好忠です。
今回は
「手書き文字を認識するAI」
の作成を通して、自分でAIを作成する手順を紹介します。
AIという言葉は曖昧なため、正確には
「ディープラーニング手法のCNNを使って、手書き文字を認識するシステム」
を作成する手順になります。
既製品のAIではなく、「独自のAIを構築する」場合の参考になればと思います。なお、ページ数などの都合もあり、ここでは「ディープラーニングとPythonに関する基礎的な知識を有している人」をターゲットに説明を進めていきます。
全体の流れとサンプルコード
今回は以下の3つのフェーズに分けて進めていきます。
-
1.訓練フェーズ
独自のCNNモデルを構築し、訓練データを使った学習を行います。
何も知らない子供に、この画像は「A」、この画像は「B」…という感じで、
文字を教えていくようなイメージになります。 -
2.評価フェーズ
きちんと学習できているか、検証データを使って評価を行います。
期待する成果が出なければ、訓練フェーズから再度やり直す事になります。 -
3.応用フェーズ
学習済みのモデルを使って、実際に「手書き文字の識別」を行います。
各フェーズのコードと実行結果は、GitHub上にJupyterNotebook形式で公開しています。以降の説明も、このGitHubで公開しているコードをベースに進めていきますので、合わせてご参照いただければと思います。
これらのファイルはGoogle Colabにインポートして実行する事も可能ですが、モデルの保存や読み込み、手書き画像の読み込み部分はパスの関係でエラーになると思われるので、環境に合わせて修正していただければと思います。
ソースコードと実行結果(GitHub)
※外部サイト:https://github.com/KurozumiGH/tf2-emnist-cnn-notebook
- 1.訓練フェーズ … 01_train.ipynb
- 2.評価フェーズ … 02_evaluate.ipynb
- 3.応用フェーズ … 03_applicate.ipynb
訓練フェーズ
Step:1-1 ~ Step:1-2
処理に必要なモジュールを読み込みます。
ディープラーニング用のフレームワークとしてTensorFlowやPyTorchなどが有名ですが、今回は産業向けによく使われるTensorFlow(v2系)を利用します。
Google colabを使う場合、必要なモジュールの多くが事前に導入されていますが、個別に環境を作成する場合は、
numpy, matplotlib, seaborn, tensorflow, opencv-python
を導入してください。
モジュールのバージョンによってはAPIの仕様が変わることもあるため、利用した主要モジュールのバージョンも参考までに載せています。
Step:1-3
訓練と評価で使用するデータを取得します。
本来であれば、自分で必要なデータを用意する必要があるのですが、アルファベットの手書き文字は「
EMNIST
」として公開されているため、今回はこのデータを利用します。
データは
(訓練用画像,訓練用正解ラベル),(評価用画像,評価用正解ラベル)
という形で取得できます。今回は訓練用に
(t_images, t_labels)
、評価用に
(v_images, v_labels)
という変数でデータを取得しています。
Step:1-4
今回使用したEMNIST-Lettersのデータは、画像サイズが28x28ピクセル、画像の数が訓練用に124,800枚、評価用に20,800枚用意されています。また、各画像ごとに正解ラベル(「この画像はA」というようなラベル)が用意されています。
EMNIST-Lettersの正解ラベルは「27カテゴリ」に分かれており、0~26の番号で正解ラベルが設定されています。(
1=A, 2=B, 3=C, 4=D, ... 26=Z
、
0
は未使用)
データはNumPyのndarray型で保持されているので
shape
でデータの形状を確認できます。例えば、訓練用画像の
t_images.shape
であれば
(124800, 28, 28)
となります。項目が3つあるので「3次元」のデータであり、各項目は
(batch=画像数, height=高さ, width=幅)
という順序になっています。
実際に、1枚目の訓練用画像(
t_images[0]
)を表示すると、次のようなイメージになります。色つきのグラフで表示しているため分かりづらいかもしれませんが、実際はグレースケールの画像で、各ピクセルの明るさは0~255までの値で表現されています。
Step:1-5
訓練を行う上では、データの範囲が揃っていたほうが好ましいため、各ピクセルの値が
0~1
の範囲に収まるように調整します。今回の画像データは各ピクセルの値が
0~255
で表現されているため、
255
で割って
0~1
の範囲になるようにしています。
また「Step1-4」で確認したように、画像データの形状は
(124800, 28, 28)
の「3次元」になっていますが、TensorFlowのCNNでは
(batch, height, width, channel)
という形状の「4次元」でデータを渡す必要があるため、
reshape
を使ってデータの形状を「3次元から4次元」に変換しています。最後の
channel
は画像のチャンネル数で、RGB情報を持ったカラー画像であれば
channel=3
、今回のEMNIST画像のように、輝度情報しか持たないグレースケール画像なら
channel=1
となります。
調整後の画像データの形状が
(124800, 28, 28, 1)
の4次元になり、輝度情報もグラフで確認すると
0~1
の範囲に収まっていることが確認できると思います。
Step:1-6
モデルのネットワーク構成を定義します。これは、ディープラーニングの「入力層、隠れ層、出力層」を定義する部分になります。複雑なモデルも定義可能ですが、今回は
keras.Sequential
を使って、層を順番に重ねていくだけのシンプルな構成にしました。
CNNを使うので、畳み込み(
Conv2D
)とマックスプーリング(
MaxPooling2D
)の組み合わせを何度か通し、後半で
Flatten
で直列化したあと完全結合し、最終的な出力はソフトマックスで27カテゴリに分類しています。(EMNIST-Lettersのカテゴリ数が27のため)
また過学習を防いで汎化性能を向上させるため、途中にドロップアウト(
Dropout
)も追加しています。
最初の層は入力データの形式を判断できないため
input_shape
で入力データの形式を指定する必要があります。今回は28x28ピクセルで1チャンネルの画像データが入力データになるため、
input_shape=(28, 28, 1)
と指定します。 2層目以降は、前の層の出力から自動で判断できるため、
input_shape
の指定は不要になります。
活性化関数が指定できる層では
activation
を使って活性化関数を指定します。よく使われる活性化関数はTensorFlowで用意されているので、例えばランプ関数(ReLU)を使いたい場合は
activation="relu"
のように指定します。
なお、シグモイド関数は微分値が小さく、層が深いと勾配消失が起きやすいため、あまりお勧めしません。特別な理由が無ければ
ReLU
の使用をお勧めします。
Step:1-7
定義したモデルを、最適化アルゴリズム(オプティマイザ)、損失関数や評価関数を指定してコンパイルし、訓練の準備を整えます。
オプティマイザなども有名なアルゴリズムはTensorFlowで実装済みなので、簡単に使用することができます。Santa-SSSなど比較的新しく発表されたアルゴリズムは実装されていませんが、独自のオプティマイザを定義することも可能なので、自分でSanta-SSSなどオプティマイザを実装して組み込むことも可能です。
モデルの情報は
model.summary()
で確認できます。モデルの構成だけでなく、各層の出力データの形状や、訓練の中で調整するパラメーターの数も確認できます。
今回のモデルでは
Total params: 598,107
となっており、約60万のパラメーターを訓練しならが調整することになります。余談ですが、最近話題になっているGPT-3は、パラメーターの数が1,750億と言われており、その膨大さが分かるかと思います。
Step:1-8
準備が整ったところで、
model.fit()
で訓練を行います。
訓練するだけなら、訓練用のデータと正解ラベル(
t_images
と
t_labels
)があればよいのですが、
validation_data
で検証用のデータを渡すと、1エポックごとに検証データの評価結果も表示されるようになり、学習の途中経過が把握しやすくなります。
モデルの構造にもよりますが、訓練には膨大な数の計算が必要になるため、多くの時間が必要になります。GPUを使えばCPUに比べて高速に計算できるので、可能であればGPUが利用できる環境での計算をお勧めします。(CPUで十数分かかる計算でも、GPUなら数秒で計算できるくらいの差があります)
Step:1-9
model.fit()
が返す履歴情報を使って、1エポックごとの状況をグラフで確認してみます。
Accuracy
が評価関数、
Loss
が損失関数による値を表しており、青線が「訓練データ」に対する評価、赤線が「検証データ」に対する評価結果になります。
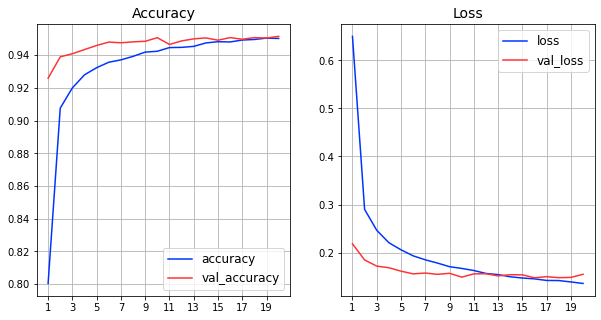
きちんと学習できていれば、エポック数を重ねるごとに訓練データに対する性能が向上していきます。検証データに対しても性能が向上していくのですが、エポック数を更に増やした場合、「検証データに対する性能が悪化に転じるポイント」が出てきます。
今回は20エポックで学習をストップしているので検証データに対する顕著な性能悪化は見られませんが、もしそのような事象が出ているようなら、「過学習」を起こした状態であるため、過学習を起こさないための対策が必要になります。(過学習を起こす前に学習をストップさせたり、ドロップアウトなど過学習を起こりづらくする対応を入れるなど)
今回は触れていませんが、TensorFlowには「結果が良くなった場合だけモデルを保存」したり「評価値が停滞した場合に学習率を変更」するような仕組みも存在するので、これらの機能をうまく利用すれば、少し多めのエポック数を回したとしても、最適な状態のモデルを取り出せるようになります。
Step:1-10
訓練が完了したモデル(学習済みモデル)は、後で簡単に利用するために、ファイルに保存しておきます。こうしておけば、再訓練をしなくても、訓練済みの状態でモデルを復元できるようになります。また、前回の続きから更に訓練を続けることも可能になります。
TensorFlowではいくつかの保存方法がありますが、今回はHDF5形式でモデルを保存します。特別なオプションを指定しなくても、
model.save()
でファイルの拡張子を
h5
にすれば、自動でHDF5形式で保存されます。
評価フェーズ
訓練フェーズの中でも、1エポックごとの評価結果を簡単に確認しましたが、ここでは、モデルの評価についてもう少し詳しく説明したいと思います。
Step:2-1 ~ Step:2-2
新しいNotebookで作業しているため、必要なモジュールと検証データを読み込みます。この部分の処理は「Step1」での処理とほぼ同じです。
Step:2-3
HDF5形式で保存しておいた学習済みモデルを読み込みます。
学習済みモデルを読み込む場合、モデルの定義は不要で、
load_model()
を呼び出すだけで元のモデルを読み込めます。確認のために
model.summary()
でモデルの状態を表示していますが、モデルの構成が復元できている事が確認できると思います。
Step:2-4
モデルの評価を行うには、
evaluate()
を使用します。評価用の画像データと正解ラベル(
v_images
と
v_labels
)を渡すことで、検証データに対する損失関数と評価関数の結果が表示されます。
Step:2-5
evaluate()
では損失関数と評価関数の結果しか分からないので、検証データが、実際どのように予測されているのか確認してみましょう。
predict()
に予測したいデータ(今回は検証用の画像データ)を渡せば、予測結果を受け取れます。
試しに予測結果の1つ(検証用画像の2番目=
v_images[1]
の画像に対する予測結果=
predictions[1]
)の値を表示すると、27個の数値が入っていることが分かります。
これは、今回のモデルが「ソフトマックスで27カテゴリに分類」した結果を出力するようになっているため、値の総和が1.0になる27個の数値(確率を表した数値)が出力されます。
ちなみに「
1.23e-03
」という表現は、
1.23×10の-3乗
という意味で、この場合は
0.00123
という数を表しています。わざわざ計算しなくても、
e
の後ろの数だけ小数点の位置をずらせば、元の数になります。
Step:2-6
予測結果を27個の数値で見ても分かりづらいので、実際の入力画像と予測結果をビジュアル的に表示して確認してみます。画像イメージの上部に、正解ラベル(
True
)と予測ラベル(
Predicted
)も表示するようにしています。
まずは、前段の「Step:2-5」で表示した
predictions[1]
の結果を表したものです。予測結果は「Aである可能性がほぼ100%」になっており、実際の正解と一致しています。

予測結果の中には、次のように複数の可能性が導き出される場合もあります。今回の実装では「最も確率の高いクラスを予測結果として採用」するようにしているため、最終的な予測結果はBとなります。私たちが見ると「Uかな?」と思う人もいると思いますが、不思議なことに「Uである可能性は0%に近い」判断結果になっています。
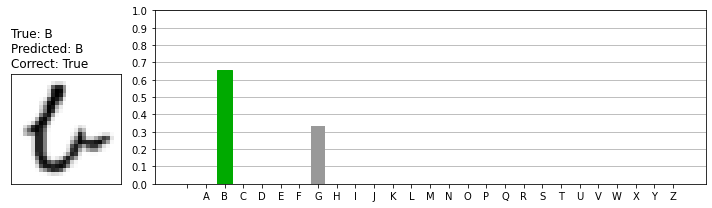
EMNIST-Lettersのデータの中には、次のように「正解ラベルが微妙なデータ」も含まれているようです。私たちが見ると多くの人が「A」と答えると思いますし、モデルの予測結果も「97~98%の確率でA」となっているのですが、正解は「G」だそうです。

Step:2-7
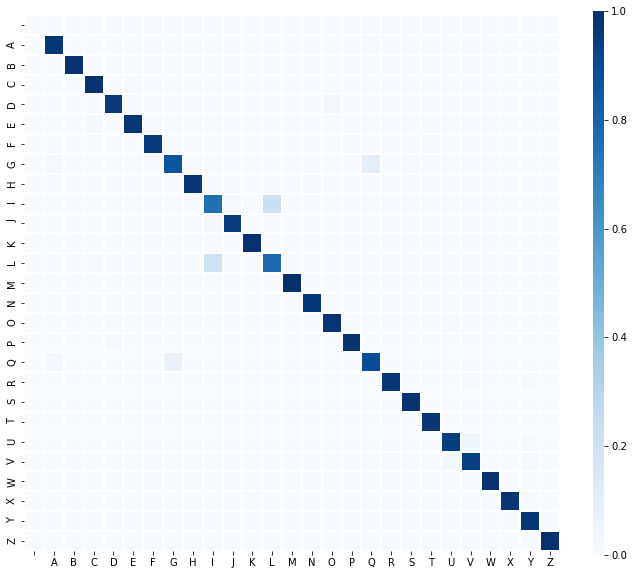
これまで予測結果の一部をピックアップして見てきましたが、検証データに関する予測結果の全体像を「混合行列のヒートマップ」で確認してみます。混合行列は自分で計算しなくても、
tf.math.confusion_matrix()
を使って簡単に計算可能です。(混合行列の計算結果をseabornを使ってヒートマップで図示しています)
縦軸が正解ラベル、横軸が予測ラベルです。
この結果を見ると、全体的に高い精度で予測ができているものの、「IとL」「GとQ」については間違いやすい事が確認できます。
応用フェーズ
応用として、学習済みモデルを使った手書き文字の識別を行ってみましょう。
画像から文字部分を抽出するには、多少の画像処理が必要になるため、今回は文字部分の抽出にOpenCVを利用しています。OpenCVはPythonからも利用することが可能で、画像データはNumPyのデータ型が使われるため、TensorFlowとの相性も抜群です。
Step:3-1
必要なモジュールを読み込みます。
特筆すべき内容はありませんが
cv2
がOpenCVです。pip経由で導入する場合は
pip install opencv-python
で導入してください。今回利用したOpenCVのバージョンは
4.3.0
になります。
Step:3-2 ~ Step:3-3
OpenCVの
i
m
read()
を使って手書き文字の画像ファイル(
letter.png
)を読み込みます。
画像データはNumPyのndarray型として読み込まれます。
読み込んだデータの形状は
(235, 830, 3)
となっており、これは、830x235ピクセルのチャンネル数が3(BGRのカラー画像)を表しています。
!OpenCVはRGBではなくBGRの順番で色情報を保持するようになっています

Step:3-4 ~ Step:3-5
このままでは1枚の画像データでしかないので、画像から文字を抽出します。
今回は、MSER(Maximally stable extremal region)を使って文字の領域を検出します。MSERを使うと、1つの文字に対しても複数の領域が検知される事があるため、指定した閾値の範囲内であれば、同じ領域とみなし重複する領域を排除するようにしています。
本来であればMSERで検出された領域に対して、縦横比など複数の観点でフィルタリングを行い文字領域だけが残るようにノイズを省いていくのですが、そこまで行くと本題から脱線してしまうため、今回は簡易的な処理に留めています。また、検出された領域(バウンディングボックス)の並び替えも、等間隔の行に文字が書かれている前提での処理としています。
最終的に、以下の赤枠で囲んだ部分を1つの文字領域として検出できました。ソートした領域の順序が分かりやすいように、順序番号も青字で表示しています。

Step:3-6 ~ Step:3-7
各文字の領域が分かったので、それぞれの文字を抽出して、「訓練データと同じような形」に変換していきます。入力データが訓練データと大きくかけ離れていると予測精度が落ちてしまうので、最終的には訓練データと同じ28x28ピクセルの画像になるように調整します。
カラー画像からグレースケール画像に変換し、各ピクセルの値が0~1に収まるように調整したあと、各文字を28x28ピクセルの画像として取り出します。検出した文字領域は長方形になっているため、長辺のサイズで正方形に整形(余白は背景色でパディング)したうえで、28x28ピクセルにリサイズしています。
このようにして得られた画像は以下のようになり、それぞれ領域サイズが異なる文字が、28x28ピクセルの画像に変換されたことを確認できます。


各文字の形状
(
shape
)
は
(28, 28, 1)
という3次元データになっているため、
np.array()
を使って、評価データと同じような、4次元形式
(batch, 28, 28, 1)
に変換します。
Step:3-8
やや準備作業が長くなりましたが、これで「手書き文字の画像データ」の準備が整いました。いよいよ学習済みモデルを使って予測を行う段階に入ります。
まずは、検証フェーズで行ったように
load_model()
を使ってHDF5形式で保存していた学習済みモデルをロードします。
Step:3-9
用意した手書きデータの画像に対して、
predict()
を使って予測を行います。予測部分も、与えているデータが「検証データ」から「独自に作成した手書き文字のデータ」に変わっただけで、基本的には検証フェーズで行った予測処理と同じです。
予測結果は
predict()
の戻り値(今回のコードでは
predictions
)に格納されるので、各文字ごとに「最も可能性が高いと判断された文字」を最終的な予測結果として出力しています。(見やすくするためにスペースを入れて表示するようにしています)
手書き文字の正解は「
TENSORFLOW IS AN END TO END OPEN SOURCE PLATFORM FOR MACHINE LEARNING
」ですが、結果を見ても分かるとおり「IをL」と間違って認識した箇所が2カ所出てしまいました。(以下の2文字)
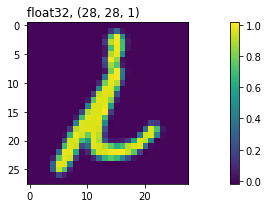
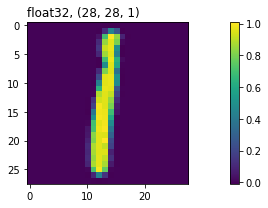
「IとL」の間違いが多いことは混合行列の結果でも分かっており、ある程度予想していた通りの結果になりました。
このように、AIは「間違った結果を導き出すこともある」という前提に立ち、より精度を高めるためには、英単語のディクショナリを併用するなど、複数のアプローチを組み合わせて使うことが重要だったりします。
最後に
文字識別のAIを作る方法について紹介してきましたが、いかがでしたでしょうか。
もう少し簡潔にまとめられると良かったのですが、やや難しい内容になってしまったかもしれません。利用する機能に合わせて「データの形状を変換」する処理が多く出てくるため、利用しているデータの形状や、NumPyの
shape
や
reshape
操作を押さえておくと理解しやすいかもしれません。
今回のコードは全て公開してあるので、実際に手を動かしながら、AI作成にチャレンジしてみてくださいね!
それでは、また次回のコラムでお会いしましょう。
当サイトの内容、テキスト、画像等の転載・転記・使用する場合は問い合わせよりご連絡下さい。
エバンジェリストによるコラムやセミナー情報、
IDグループからのお知らせなどをメルマガでお届けしています。



