
黒住 好忠
こんにちは。テクニカルスペシャリストの黒住です。
最近では、テレワークによる働き方改革などもあり、カメラやマイクと言ったデバイスも、一般的に利用できるケースが増えてきました。そこで今回は「AI×カメラ」による、オンライン時代の「新しいインターフェース」を作成してみたいと思います。
AIカメラによる新しいインターフェース
今回は「カメラ経由で目線をコントロールする」インターフェースを作成します。これは、「仮想空間上にあるアバターの目線を、一般的なWebカメラを使って動かす」というもので、マウスやキーボードなどを使わなくても、カメラ経由でアバターの操作が行えるようになるものです。
人間のコミュニケーションに重要な目線
人間は「目線によるコミュニケーション」を多く使うように進化した動物で、ちょっとしたコミュニケーションであっても、相手の目線から多くの情報を読み取っています。他の動物と比べて、目の「白目」部分が多いことも、目線を多用することと深い関係があると言われています。
そのため、人間のコミュニケーションでは「目線」が重要な要素の1つになってくるのですが、実際のオンライン会議では、画像サイズなどの関係で目線が分からない場合や、そもそもカメラ自体をオフにしているケースも数多く見受けられます。
このようなケースにおいて、目線をコントロールできるアバターが使えるようになれば、より柔軟なコミュニケーションが可能になります。
メタバースへの展開も可能
また、最近知名度が増えてきた「メタバース」ですが、今回のインターフェースはメタバースの世界でも活用できます。コミュニケーションを目的としたメタバースの世界では、アバターを介したコミュニケーション手法が多く使われるのですが、今回のインターフェースを使えば、アバター自体に現実世界の表情をリンクさせることも可能になります。
一般的に、3Dで構築された仮想空間上では専用のヘッドセットや入力デバイスが必要になるケースも多いのですが、今回のインターフェースは、一般的なWebカメラだけで実現できるという点も大きな特徴になります。
処理の流れ
今回作成する新しいインターフェースは、以下の5つのステップで処理を行っています。
カメラによるアバターのコントロールだけであれば最後のステップは不要なのですが、今回は「アバターの状態を仮想カメラに出力」して、ZoomやTeamsなどの一般的なコミュニケーションソフトから映像を配信できるようにしています。
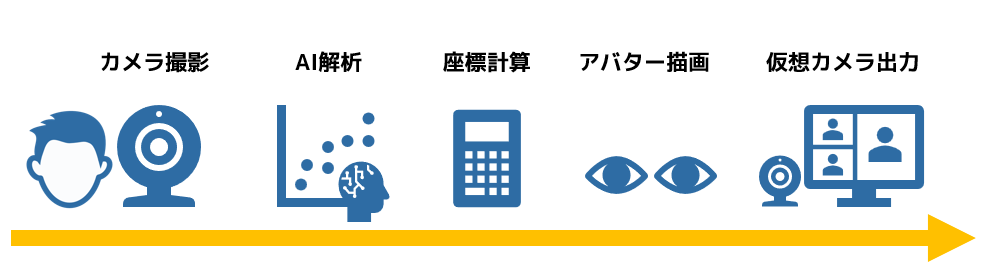
- カメラで映像を撮影
- 撮影画像から顔の座標を推論(AI使用)
- 座標から目的の特徴を計算
- 特徴をアバターに反映
- アバター画像を仮想カメラに出力
カメラで映像を撮影
まずは、Webカメラからの映像を画像として取得します。
コンピュータービジョンで有名なOpenCVを利用して「1280×720ピクセル、30fps」の設定で、カメラの画像を取り込みます。OpenCVの内部では、カラー情報が「BGR」の順序で格納されており、一般的な「RGB」とは逆順になっているので、ご注意ください。
撮影画像から顔の座標を推論(AI使用)
カメラから取得した画像をAIで解析し、顔を構成するパーツ(ランドマーク)の座標を推論させます。
最初からAIモデルを作成すると大変なのですが、世の中には「既に学習済みのモデル」が大量に公開されているので、今回は公開済みのモデルを使用します。
色々なモデルが存在するのですが、今回はGoogleから「Apache License 2.0」ライセンスで公開されている「MediaPipe」を採用しました。
各ランドマークの推論
MediaPipeのFaceMeshを使って処理を行うと、「478箇所のランドマーク」情報を取得できます。各ランドマークは、あらかじめ決められた顔の部位(例えば左目の左端部分・・・など)に対応しており、それぞれのランドマークが「X,Y,Z座標」を保持しています。
MediaPipeから取得した値はNormalizedLandmarkList型で扱いづらいため、以下のような処理で[X,Y]座標だけのnumpy.ndarray型に変換しています。(Z座標は使わないので除外しています)
なお、ランドマークのX,Y座標は0.0~1.0の範囲でノーマライズされているので、画像ピクセル上での座標を求めたい場合は、それぞれ、画像の幅と高さを掛ける必要があります。
ランドマーク番号との対応
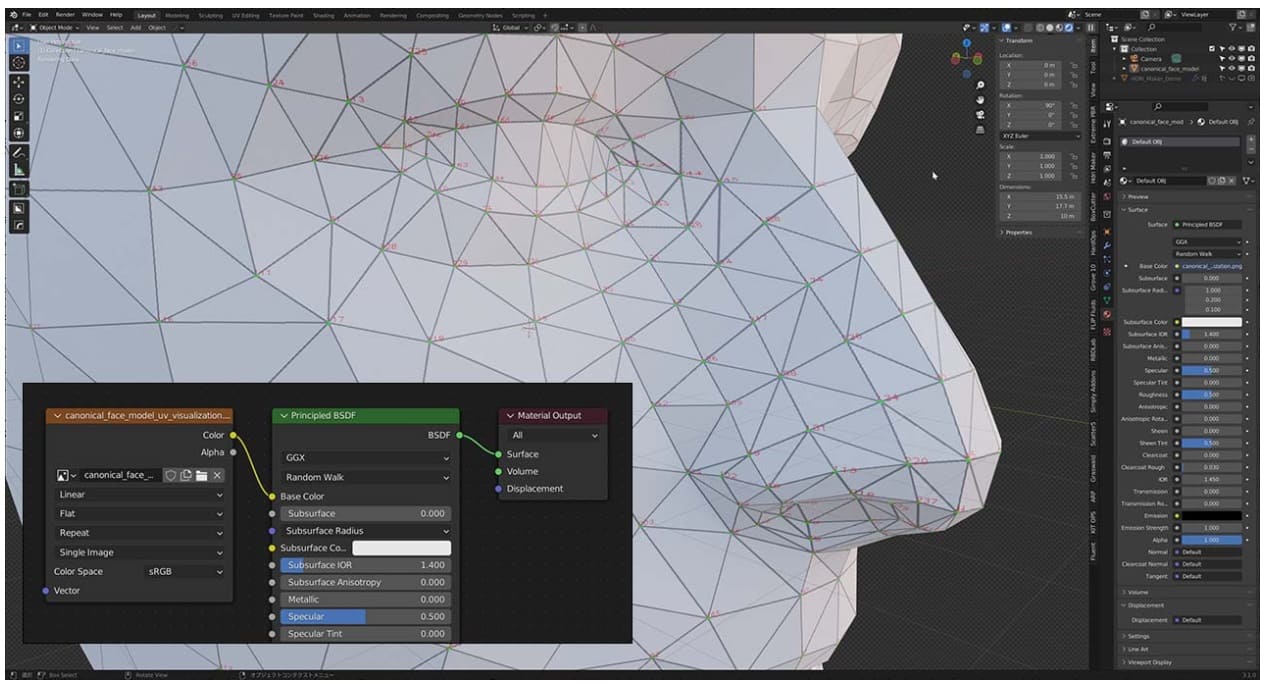
解析結果は、478個のランドマーク情報で表されるため、そのままでは「それぞれのランドマークが、顔のどの部分を指しているのか」分かりません。例えば、鼻の頂点部分の座標を取得したい場合、鼻の頂点部分に対応したランドマークが「何番目のランドマークで表現されているのか」を知る必要があります。
幸い、MediaPipeのGitHubリポジトリで、UV展開された3Dモデルと頂点番号付きのテクスチャ画像ファイルが公開されているので、Blenderなどの3DCGソフトでモデルファイルを開き、テクスチャマップを設定すれば、各頂点のランドマーク番号を視覚的に確認できます。
座標から目的の特徴を計算
ランドマーク情報から、目的となる目の座標(目の左端、右端、上端、下端、虹彩の座標)を特定できたら、その座標を元に「実際の目線の位置(虹彩の位置)」を計算します。
カメラに写っている画像は、顔やカメラの位置、角度などの影響を受け、「必ずしも正面から見た、まっすぐな画像にはならない」ため、単純に各軸(X軸、Y軸)単位での計算はできません。例えば、顔を90度横に傾けた場合、実際の上下方向は画像上では横方向(X軸方向)、実際の左右方向は画像上では縦方向(Y軸方向)となり、X軸とY軸が逆になります。
そのため、今回はホモグラフィ変換を利用して、角度などに関係なく虹彩の位置を特定できるようにしました。理論は難しいかもしれませんが、簡単に言うと「歪んだ画像をまっすぐに補正する」ような処理です。
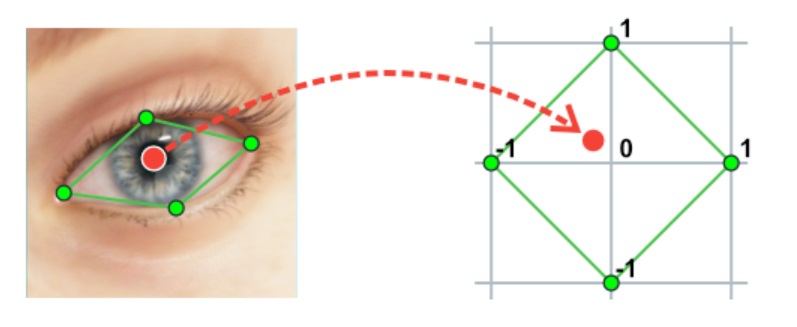
具体的には、AIで検出した「上下左右の目の頂点座標」を「-1.0~1.0のひし形の座標」に変換する変換行列を求め、その行列を使って虹彩の位置を計算しています。
なお、変換行列を求める際の「変換先の座標」に決まりはないのですが、今回は「目の中心を0として、上下左右にそれぞれ-1.0~1.0の比率」として簡単に扱いたかったため「-1.0~1.0のひし形」にしています。
また、「目線」以外に「目の開閉状態」、つまり「目をどのくらい開けているか」の情報も取得するようにしています。
目の開閉状態は「目の上下座標の距離(L2ノルム)」を使えば求められそうなのですが、開閉状態も「0.0~1.0:目を完全に閉じている~全開」の範囲で表したかったので、次のように工夫しています。
単純に距離だけを使う場合、目を閉じた状態は判断できる(距離が0になる)のですが、目を全開にしているかどうかは、「そもそも目を全開したときの距離が未知数」のため単純に求めることができません。そこで「虹彩の上下座標の距離=目を最大まで開いたときの距離」と仮定して、「目の上下座標の距離÷虹彩の直径」を「目の開閉率」として扱っています。
実際には、個人差や検出した座標のブレなどの影響もあり、計算結果が1.0を超えることもあるので、最終的には「0.0~1.0」の範囲に収まるようなクリッピング処理も行っています。
特徴をアバターに反映
ここまで来れば、「目線の相対的な位置(-1.0~1.0)」と「目の開閉率(0.0~1.0)」が算出できているので、後はその内容をアバターに反映させるだけです。
それなりのアバター画像があれば見た目も良くなるのですが、今回は簡単なサンプルという事もあり、「楕円で簡易的な目を描画するだけ」に留めています。目の開閉率で縦方向のサイズを調整し、目線の相対的な位置に合わせて虹彩を描画するようにしています。
# 簡易的に目を描画する関数
def draw_eye(frame, center_x, center_y, iris_x_ratio, iris_y_ratio, open_ratio):
w, h = 220, int(200 * open_ratio)
iris_x = int(center_x + w * iris_x_ratio)
iris_y = int(center_y + h * -iris_y_ratio)
cv2.ellipse(frame, ((center_x, center_y), (w, h), 0), (0xE7, 0xE7, 0xE7), -1)
cv2.circle(frame, (iris_x, iris_y), int(h / 2.4), (0xCC, 0x99, 0x66), -1)
cv2.circle(frame, (iris_x, iris_y), int(h / 6.0), (0x00, 0x00, 0x00), -1)アバター画像を仮想カメラに出力
ここまでの処理で「カメラによるアバターを操作するインターフェース」は作成できているのですが、せっかくなので、描画したアバター画像を「仮想カメラ」に出力できるようにします。
仮想カメラは、ZoomやTeamsなどの一般的なコミュニケーションソフトから「通常のWebカメラ」として認識されるため、カメラを切り替えるだけで「アバターの映像をそのまま配信できる」ようになります。
DirectShowなどを使って仮想カメラを作成する方法もあるのですが、今回は「OBS Studioとpyvirtualcam」を組み合わせて、手軽に仮想カメラを使えるようにしています。なお、pyvirtualcamのライセンスは、一定条件においてソース開示義務のある「GPL-2.0 License」となっているため、利用する際にはご注意ください。
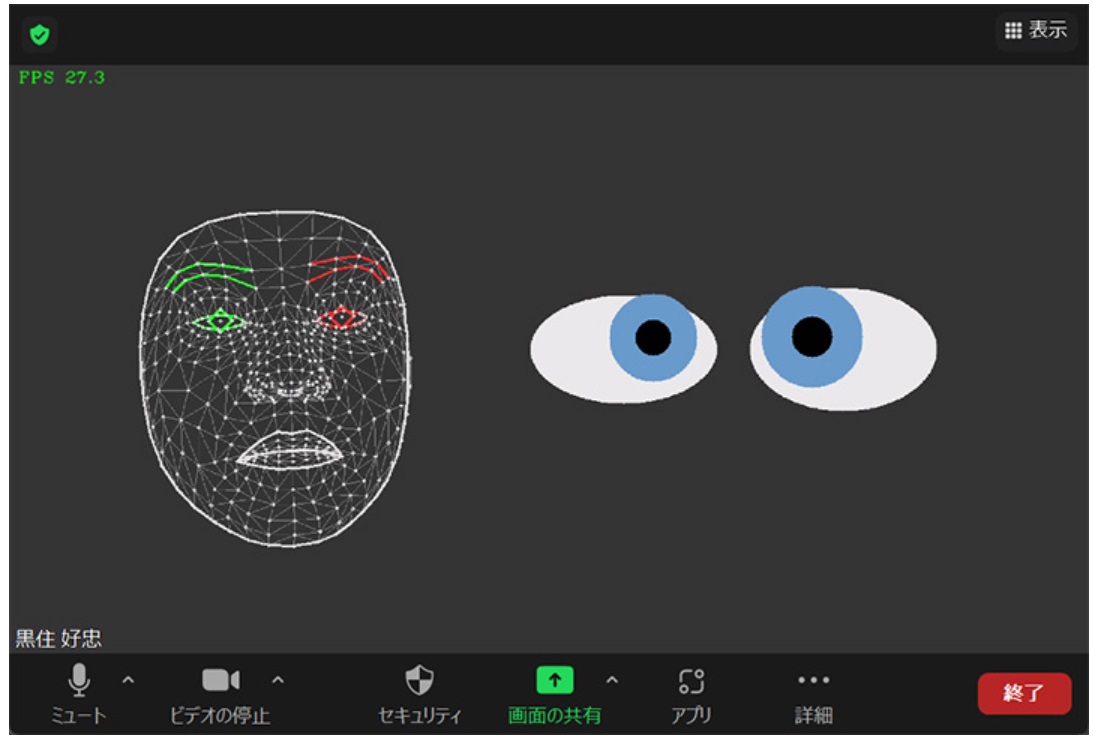
Zoomで仮想カメラの映像を表示させた場合、以下のような感じになります。見た目はさておき、独自に描画したアバター画像が、Zoom画面上に表示されているのが分かると思います。(実際には、リアルタイムで顔の動きに合わせて目線などが動きます)
今回は、GPUは利用せず、CPU処理のみ(Intel MKLも未使用)で、1280x720ピクセルのカメラ画像に対して処理を行っていますが、30fpsに近い十分なパフォーマンスが出ています。
最後に
今回は、「カメラを使ったインターフェース作成」についてご紹介しましたが、いかがでしたでしょうか。
カメラやマイクは、「そのまま映像や音声を伝えるだけ」のデバイスとして利用されがちですが、AIなどと組み合わせると、新しい活用方法が見つかることもあります。
今回は、シンプルに「目のコントロール」のみでしたが、3Dモデルを利用している場合は、Z座標も含めたランドマークと3Dモデルをリンクさせた、より柔軟な表現も可能になります。また、2Dであっても、他のランドマーク情報を活用して、口や眉などの、目以外の情報を反映させることも可能です。
アイデア次第で色々な活用方法があるので、固定概念にとらわれず、新しい可能性を模索してみてくださいね。
それでは、また次回のコラムでお会いしましょう。
リンク集(全て外部リンク)
- MediaPipe(オープンソースの機械学習ソリューション)
- MediaPipe face_geometry data(顔の3Dモデルとテクスチャファイル)
- Blender(3DCGソフトウェア)
- OpenCV(コンピュータービジョン用ライブラリ)
- pyvirtualcam(OBS Studioの仮想カメラを使うためのライブラリ)
- OBS Studio(ストリーミング配信ソフトウェア)
当サイトの内容、テキスト、画像等の転載・転記・使用する場合は問い合わせよりご連絡下さい。
エバンジェリストによるコラムやIDグループからのお知らせなどを
メルマガでお届けしています。





