
関連するソリューション

業務改革
AI
IDアメリカ
ハムザ・アフメッド
ODSC(Open Data Science Conference)は、世界最大級のAIイベントで、大規模言語モデル(Large Language Models:LLM)や画像技術のAIから医療分野への応用まで、多様なトピックを網羅しています。去る4月23日~25日にボストンで開催されたODSC East 2024では、LLMを中心としたディスカッションが行われ、様々な分野の専門家がそれぞれの見識を披露しました。
本レポートでは、私が参加した同イベントのディスカッションから浮かび上がったLLMに関する重要なポイントを掘り下げます。
ローカルLMMの時代
過去2年間、ChatGPTや類似ベンダーのLLMは、その巨大な規模と範囲により、LLMの風景を支配してきました。GPT-4は1兆をはるかに超えるパラメーターを誇り、2万5千のGPUを収容するGPUファームで動作し、それぞれが約50,000ドルという高額な値札を付けています。
2022年以降、オープンソースの代替製品が利用できるようになりましたが、これらの巨大なモデルの能力とは比較になりませんでした。しかし、潮目は変わり始めています。ローカルLLMは大きな進化を遂げ、今や最大規模のLLMとさえ真っ向から戦えるようになってきました。
リーダーボードを見ると、すでに新しいLlama 3 70Bが上位に登場し始めています。コンシューマーグレードのハードウェアで動作するこのモデルは、GPT-3.5ターボに匹敵する性能を達成しています。
2022年以降、オープンソースの代替製品が利用できるようになりましたが、これらの巨大なモデルの能力とは比較になりませんでした。しかし、潮目は変わり始めています。ローカルLLMは大きな進化を遂げ、今や最大規模のLLMとさえ真っ向から戦えるようになってきました。
リーダーボードを見ると、すでに新しいLlama 3 70Bが上位に登場し始めています。コンシューマーグレードのハードウェアで動作するこのモデルは、GPT-3.5ターボに匹敵する性能を達成しています。
ファインチューンのコスト
過去1年間で、モデルの微調整にかかるコストは著しく減少し、数百万ドルからわずか数百ドルにまで激減し、この劇的な変化は、LoRAやQLoRAのような新しいファインチューニング手法の採用によるもので、より小さな精度のバッチを利用して、より効率的にモデルをトレーニングできるようになりました。
訓練コスト削減のもう一つの要因は、AIハードウェアの利用可能性が高まったことです。以前は主にNvidia GPUがトレーニングに使用されていましたが、AMDの新しいMI300 GPUや、LLMを低コストでトレーニングできる様々なベンダーの多数のCPUが登場し、状況は多様化しています。さらに、サードパーティベンダーは、LLMの広範な知識を必要としないトレーニングプラットフォームを提供するようになり、モデルの微調整への参入障壁が低くなっています。
さらに、異なるタスクに最適化された2つのLLMを結合し、ウェイトを更新した新しいLLMを作成できる、モデル結合のような技術も登場しています。このプロセスには最小限のコンピューティングしか必要としませんが、結果は大幅に改善されます。このような手法を洗練させるためには、依然として実験が欠かせないが、自らテストを行う個人の数が増えることで、これらの手法の理解と採用が加速することが期待されます。
訓練コスト削減のもう一つの要因は、AIハードウェアの利用可能性が高まったことです。以前は主にNvidia GPUがトレーニングに使用されていましたが、AMDの新しいMI300 GPUや、LLMを低コストでトレーニングできる様々なベンダーの多数のCPUが登場し、状況は多様化しています。さらに、サードパーティベンダーは、LLMの広範な知識を必要としないトレーニングプラットフォームを提供するようになり、モデルの微調整への参入障壁が低くなっています。
さらに、異なるタスクに最適化された2つのLLMを結合し、ウェイトを更新した新しいLLMを作成できる、モデル結合のような技術も登場しています。このプロセスには最小限のコンピューティングしか必要としませんが、結果は大幅に改善されます。このような手法を洗練させるためには、依然として実験が欠かせないが、自らテストを行う個人の数が増えることで、これらの手法の理解と採用が加速することが期待されます。
モデルではなくデータに集中する
モデルの進歩に注目が集まりがちですが、これらのモデルは一過性のものであることを認識することが重要です。わずか1年の間に、Meta社が最先端のLLMの3回目の反復をリリースし、この技術に基づいて微調整された改良型モデルが何千と普及するのを目の当たりにしています。モデルは今後も出現し続けますが、このような流動的な状況の中で、不変なのがデータです。高品質なデータは、この技術の礎であり、使用するモデルに関係なく、一貫して不可欠で貴重なものです。データは、新しいモデルの機能を構築するための土台となります。プレゼンターからのアドバイスは、最新モデルの追求よりも、高品質なデータの作成を優先することの重要性を強調していました。結局のところ、LLMの真の可能性を決めるのはデータの質であるとのことです。管理システム(RMS)
レストランマネージメントシステム(RMS)は、レストラン、バー、フードトラックなどのフードサービス業界における複雑な需要に対応するために細心の注意を払って作られたPOS(販売時点情報管理)ソフトウェアの特殊なカテゴリーです。
従来のPOSシステムとは一線を画すRMSは、在庫管理やスタッフの監視といった重要な側面を網羅する包括的なバックエンド機能を提供します。スムーズな決済処理と注文管理を容易にするだけでなく、これらの洗練されたシステムは、一般的に担当者が行う様々な作業を合理化します。
売上追跡、従業員スケジュール、給与処理などの重要な業務を統一されたデジタルプラットフォームに一元化することで、RMSは管理における間接費を削減しながら業務効率を大幅に向上させます。重要なデータを単一のインターフェイスに統合することで、管理業務が簡素化されるだけでなく、経営管理に対するコスト効率の高いアプローチも促進させます。
さらに、RMS プラットフォームの進化は、基本的な機能にとどまらず、レストラン業界の進化するニーズに対応した継続的な機能強化にまで及んでいます。最近の進歩では、モバイルベースの時間管理ツール、包括的なレビュー分析機能、顧客にパーソナライズされた電子メールなどの自動化された販売支援イニシアチブの統合が見らます。
これらの付加価値機能により、レストランはリソースをより効率的に配分できるようになり、生産性と収益性を最大化しながら、利用客に比類ないサービス体験を提供することに努力を集中できるようになります。
従来のPOSシステムとは一線を画すRMSは、在庫管理やスタッフの監視といった重要な側面を網羅する包括的なバックエンド機能を提供します。スムーズな決済処理と注文管理を容易にするだけでなく、これらの洗練されたシステムは、一般的に担当者が行う様々な作業を合理化します。
売上追跡、従業員スケジュール、給与処理などの重要な業務を統一されたデジタルプラットフォームに一元化することで、RMSは管理における間接費を削減しながら業務効率を大幅に向上させます。重要なデータを単一のインターフェイスに統合することで、管理業務が簡素化されるだけでなく、経営管理に対するコスト効率の高いアプローチも促進させます。
さらに、RMS プラットフォームの進化は、基本的な機能にとどまらず、レストラン業界の進化するニーズに対応した継続的な機能強化にまで及んでいます。最近の進歩では、モバイルベースの時間管理ツール、包括的なレビュー分析機能、顧客にパーソナライズされた電子メールなどの自動化された販売支援イニシアチブの統合が見らます。
これらの付加価値機能により、レストランはリソースをより効率的に配分できるようになり、生産性と収益性を最大化しながら、利用客に比類ないサービス体験を提供することに努力を集中できるようになります。
Llama3の紹介
このイベントの中で、Meta社はオープンソースのLLMの最新版であるLlama 3を発表しました。Llamaの旅は、2023年2月のベースモデルのリリースから始まり、その後、この1年間にパフォーマンスを大幅に向上させる改良が繰り返されてきました。Meta社が2024年5月にリリースするLlama 3は、Llama 2によって築かれた土台の上に、この進化の次のステップを踏み出すものです。
最も広く採用されているオープンソースのLLMとして有名なLlamaの新バージョンは、毎回世界中の専門家から大きな期待を集めています
最も広く採用されているオープンソースのLLMとして有名なLlamaの新バージョンは、毎回世界中の専門家から大きな期待を集めています
Llama3 vs Llama2
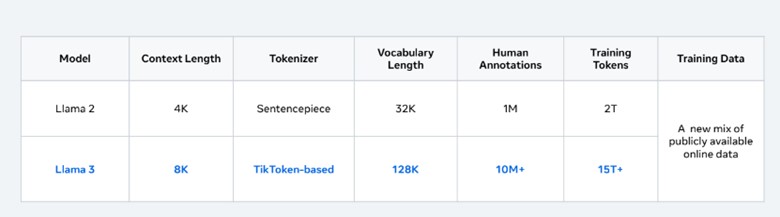
変更点を確認し、それがどのように改善につながるかを見てみましょう:
- トークナイザー(Tokenizer): トークナイザーはLLMにとって不可欠です。これはテキストをトークンとして知られる、より小さなサブワード単位に分解します。Llama 3で、Meta社はトークナイザーをSentencepieceからTiktokenベースに変更しました。この利点はあまり議論されていませんでした。
- 語彙の長さ(Vocabulary Length): 語彙を増やすことで、より広範な言語パターンや表現を扱えるようになり、さまざまなタスクやドメインに対する汎用性と適応性が高まります。語彙の長さを4倍に増やすことで、Llama 3は様々な文体や表現に対応できることが期待できます。
- 人間の注釈(Human Annotations): アノテーションは、言語ニュアンスに対するモデルの理解を深め、首尾一貫した文脈に適した応答を生成する能力を向上させます。一般的に時間がかかりますが、通常はアウトプットの品質に大きな影響を与えます。Llama 3では、アノテーションの処理量は10倍に増加しました。
- トレーニング・トークン(Training Token): トレーニング・データセットが大きくなることで、モデルのロ性能と汎化能力が向上し、さまざまなタスクやシナリオでパフォーマンスが向上します。Llama 3では、以前のイテレーションに比べて7倍以上になっています。
Llama3 400Bの発表
イベント中、Meta社は最新の製品であるLlama 3の400Bを発表しました。これは、Meta社が提供するオープンソースの公式ベースモデルとしては、これまでで最大のものです。まだトレーニング段階であり、リリースはされていませんが、予備的な結果は有望なパフォーマンスを示しています。
400Bモデルは、そのサイズと計算要件から、ほとんどの消費者には手が届かないかもしれませんが、このような大規模モデルをサポートするリソースを持つ企業では非常に支持されると思われます。
400Bモデルは、そのサイズと計算要件から、ほとんどの消費者には手が届かないかもしれませんが、このような大規模モデルをサポートするリソースを持つ企業では非常に支持されると思われます。
Llama3を試す
PCのスペックとは異なり、LLMの有効性をスペックだけで判断する確実な方法はまだありません。Metaは現在、ウェブサイトを通じて、Llama 3モデルをテストする方法を提供しています。
RAGとファインチューン
現在、データ出力の質を高めるための主な方法は、プロンプト・エンジニアリング、RAG(Retrieval-Augmented Generation)、ファインチューニングの3つです。これらのアプローチはそれぞれ、LLMの出力を向上させる手段として機能します。手法の選択は、利用可能なリソース、専門知識、希望する出力特性など、さまざまな要因によって決まります。
カスタムLLMの開発に携わる専門家は、特定のユースケースに合わせてモデルを最適化するために、これらの手法の1つ以上を採用することが多いです。
カスタムLLMの開発に携わる専門家は、特定のユースケースに合わせてモデルを最適化するために、これらの手法の1つ以上を採用することが多いです。
- プロンプト・エンジニアリング
プロンプト・エンジニアリングとは、言語モデルやAIシステムから正確な応答や結果を得るために、特定の質問や指示を作成するようなものです。目的地までの明確な道順を示すようなものです。プロンプトを注意深く設計することで、利用者が求めているタイプの回答を生成するようにAIを導くことができます。AIがユーザの求めていることを理解し、それに応じて回答できるように、質問やタスクをフレーミングすることが重要なのです。
【メリット】- 低コスト:エンドユーザがクエリをより効果的に構成するだけで、より質の高いアウトプットが得られるため、モデルのアウトプットを向上させながら、コストは実質的にゼロにできます。
- 参入障壁が低い: 目的のデータを得るための最も効果的な方法を見つけるための試行錯誤を行うだけで、プロンプト・エンジニアリングを行うための前提条件はありません。
- 幻覚が少ない: インプットを特定することで、例えばファクトチェックを求めるようなクエリで幻覚を減らすことができます。
【制限事項】 - モデルの改良はほとんどない: モデル自体に変化がないため、実際のモデルを改良することができません。
- 限定されたユースケース:モデルが変更されていないため、より微妙な回答を必要とする特定のユースケースに合わせることができない可能性があります。
- 検索拡張生成(RAG)
RAGとは、検索と生成という2つの強力なAI技術を組み合わせた言葉です。それを分解してみましょう:
- 検索(Retrieval): この部分は、与えられたトピックや質問に関連するデータや文章を見つけるために、情報の大規模なデータベースを検索することを含みます。大きな図書館や検索エンジンで情報を探すようなものです。
- 生成(Generation): ここでAIは、検索された情報に基づいて新しいテキストやコンテンツを生成します。検索中に見つかった関連性のある部分を取り出し、それを使って新鮮な回答や記事を作成するようなものです。
つまり、RAGでこの2つを組み合わせると、AIが関連情報を検索し、その情報を使って新しいコンテンツを生成するシステムを作ることになります。このアプローチは、既存の情報の検索と新しいコンテンツの生成の両方の長所を兼ね備えているため、質問回答やコンテンツ作成のようなタスクに非常に便利です。
【利点】 - 比較的低コスト:インフラがすでに構築されていれば、LLMを情報を含むデータベースに接続するのにそれほど費用はかかりません。
- 幻覚の減少: モデルにはデータとのファクトチェックが要求されるため、幻覚を減らすことができます。
- 能力の向上: データベースはより新しい情報で更新することができるため、LLMはそれまで学習したカットオフデータに制限されることなく、生きた情報を取得し続けることができます。
【制限事項】 - 高品質のデータが必要: データ検索に頼ってデータを生成するため、データをうまく整理・分類する必要があります。データサイエンティストがデータを収集し、分類するのに要する時間は、全体の80%とも言われています。
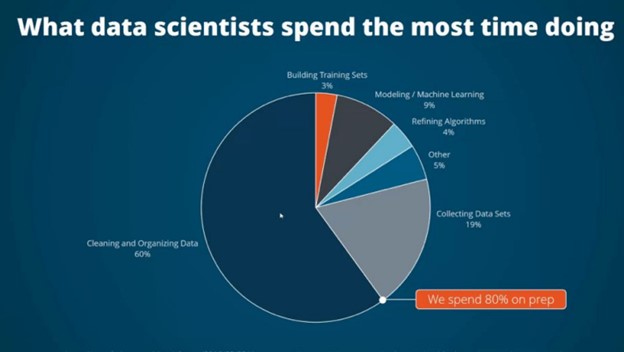
- スケーラビリティへの懸念: データベースが大きくなるにつれ、データの複雑さが増し、LLMに悪影響を及ぼす可能性があります。実行により多くのリソースを必要としたり、場合によっては幻覚を見ることさえあります。
- 微調整(ファインチューン)
この大規模なデータセットでモデルがトレーニングされると、微調整が必要になります。これは、より小さな、より特定のデータセットで、モデルに特別なトレーニングセッションを与えるようなものです。この小さなデータセットは、モデルに良い結果を出させたい特定のタスクやドメインに関連したものです。
【利点】- ユースケースの増加:その分野のデータセットを使ってトレーニングすることで、LLMが使えるユースケースの種類を大幅に増やすことができます。よく使われるユースケースとしては、医療や金融などがあります。
- 幻覚を減らす: 特定の分野の知識ベースを向上させるデータを追加することで、幻覚を減らすことができます。
- トレーニング時間の短縮:トレーニングに必要な計算資源はごくわずかであり、ゼロから作成するよりもわずかな時間で行うことができます。
【制限事項】 - LLMのパフォーマンスを低下させる可能性がある: ファインチューニングは一般的にLLMのパフォーマンスを向上させますが、他の指標におけるパフォーマンスを低下させる可能性もあります。そのため、リリース前に微調整したモデルのテストが必要です。
- データに依存する: データが不十分であったり低品質であったりすると、LLMのパフォーマンスに悪影響を及ぼす可能性があります。ファインチューンの時はできるだけ質の高いデータセットを集めることが重要です。
LLMの脅威と防御
新興テクノロジーであるLLMの脆弱性については、未知の部分が多いです。LLMを通じて発生したハッキングはあまり報告されていませんが、より多くの企業がますます機密性の高い領域でLLMを利用しようとすればするほど、ハッカーはこれらのツールを悪用する方法を考え始めると思われます。Hugging Facesに存在するモデルのいくつかは、すでに脆弱性が報告されています。
モデル・シリアライゼーションの攻撃(MSA)
ModelScanから、MSAの定義を以下に引用する:
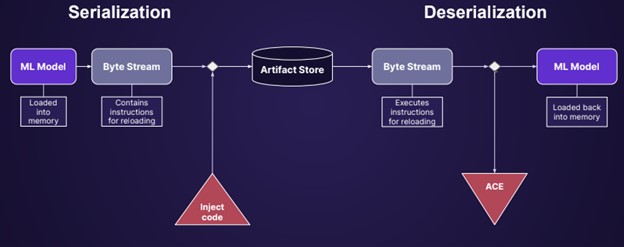
モデルは自動化されたパイプラインから作成されることもあれば、データサイエンティストのラップトップから作成されることもあります。いずれの場合も、モデルが使用され、広く採用される前に、あるコンピュータから別のコンピュータに移動する必要があります。モデルをエクスポートするプロセスはシリアライゼーションと呼ばれ、他の人が使用できるようにモデルを特定のファイルにパッケージ化します。
モデルのシリアライゼーション攻撃は、配布前のシリアライゼーション(保存)の間に、悪意のあるコードがモデルのコンテンツに追加されるもので、トロイの木馬の現代版です。
この攻撃は、モデルの保存とロードのプロセスを悪用することで機能します。例えば、model = torch.load(PATH)でモデルをロードすると、PyTorchはファイルの中身を開き、中のコードを実行し始めます。モデルをロードした瞬間にエクスプロイトが実行されます。
モデルのシリアライズ攻撃は実行に使用できます:
モデルは自動化されたパイプラインから作成されることもあれば、データサイエンティストのラップトップから作成されることもあります。いずれの場合も、モデルが使用され、広く採用される前に、あるコンピュータから別のコンピュータに移動する必要があります。モデルをエクスポートするプロセスはシリアライゼーションと呼ばれ、他の人が使用できるようにモデルを特定のファイルにパッケージ化します。
モデルのシリアライゼーション攻撃は、配布前のシリアライゼーション(保存)の間に、悪意のあるコードがモデルのコンテンツに追加されるもので、トロイの木馬の現代版です。
この攻撃は、モデルの保存とロードのプロセスを悪用することで機能します。例えば、model = torch.load(PATH)でモデルをロードすると、PyTorchはファイルの中身を開き、中のコードを実行し始めます。モデルをロードした瞬間にエクスプロイトが実行されます。
モデルのシリアライズ攻撃は実行に使用できます:
- クレデンシャルの盗難:環境内の他のシステムにデータを書き込んだり読み込んだりするためのクラウド認証情報。
- 推論データの汚染:モデルがタスクを実行した後に送信されるデータ。
- 推論データの盗難:モデルに送信されるリクエスト。
- モデルポイズニング:モデルの結果そのものを改ざんする。
モデルではなくデータに集中するモデルをロードしているインスタンスの認証情報を使用して、トレーニングデータのような他の資産を攻撃します。
古典的なアンチウイルス・ソフトウェアである ClamAV には、現在のところ MSA を検出する機能はありません。
古典的なアンチウイルス・ソフトウェアである ClamAV には、現在のところ MSA を検出する機能はありません。
脆弱なLLM
報告によると、Hugging Faceで利用可能な3354のモデルは、モデル盗用攻撃(MSA)を可能にするような構造になっています。Hugging Faceはこのような脆弱性を特定するために独自の緩和ツールを提供していますが、これらの事例の40%近くを見逃しています。侵害されたモデルは最小限のリスクで簡単に共有され、多くの場合、広く認知された名前を利用して、無防備な被害者を陥れます。
Hugging Faceは、これらのファイルを検出するためにClamAVとPickleScanを採用していますが、多くの不審なファイルは依然として検出を回避しています。注目すべきことに、Hugging Faceは文書で次のように強調している:
「何かが安全かどうかをチェックするのは、ユーザとしての責任です。」
LLMを利用するユーザは、利用する前に認識を高め、十分な注意を払うべきです。
Hugging Faceは、これらのファイルを検出するためにClamAVとPickleScanを採用していますが、多くの不審なファイルは依然として検出を回避しています。注目すべきことに、Hugging Faceは文書で次のように強調している:
「何かが安全かどうかをチェックするのは、ユーザとしての責任です。」
LLMを利用するユーザは、利用する前に認識を高め、十分な注意を払うべきです。
緩和策
悪意のあるLLMから身を守るための緩和策はいくつかあります。ModelScan: MSAを検出するオープンソースツール
- Githubリポジトリで利用可能な無料のオープンソースツールです。
- デシリアライズする必要がなく、悪意のあるオペレータを検出します。
- すべてのpickle派生形式と他のほとんどの主要なモデル形式をサポートしています。
モデルをスキャンするタイミング
トレーニング前、パブリッシュ前、デプロイ前の3つの時点でスキャンする必要があります。
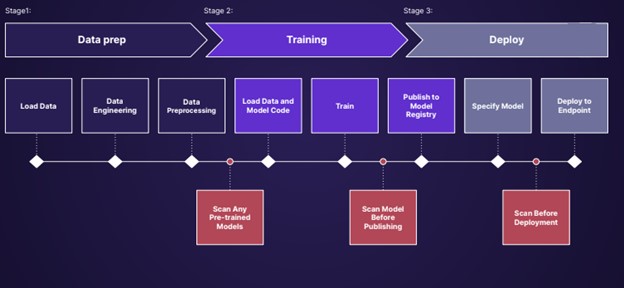
ワークフローにスキャンを追加することで、悪意のあるLLMが環境に展開されるリスクを劇的に減らすことができます。
ワークフローにスキャンを追加することで、悪意のあるLLMが環境に展開されるリスクを劇的に減らすことができます。
ゼロ・トラストの維持
一旦スキャンされ、安全であることが確認されたとしても、環境を安全に維持し続けるための対策が必要であることに注意することが重要です。例えば、MLFlowは機械学習モデルを管理し、Rest API用のダウンストリームツールを提供するために使用される人気のあるコンポーネントですが、システムの完全な乗っ取りを可能にする20以上の脆弱性が発見されています。セキュアでない環境では、独自のモデルが盗まれたり、改ざんされたりする可能性もあります。S3環境の46%は不適切に設定されており、侵入されるリスクが高いと推定されています。
そのため、LLMが安全に使用できることを確認するために、ゼロトラストアーキテクチャを維持することが推奨されています。ベストプラクティスは、週に1回ほどモデルをスキャンして安全性を確認することです。
最後に
LLMを取り巻く環境は急速なスピードで進化しており、ほぼ毎日のように改良が加えられている。数年前に常識だとされていたことも、今では時代遅れとなっていて、今日の知識も来年には時代遅れになる可能性が高いです。このような進化に対応することは極めて重要ですが、不変の側面であるデータとセキュリティを強化することがますます重要になっています。
高品質のデータは常に最重要であるが、LLM技術の進歩に伴い、堅牢なデータ・インフラに投資している企業は明確な優位性を享受することになります。さらに、変化し続けるデジタル環境において、セキュリティは依然として揺るぎない懸念事項です。ゼロ・トラストやデータ・セキュリティといったプラクティスは、今後もシステムを保護するために不可欠なものです。
デジタル環境の敵対性が高まるにつれ、強固なセキュリティ対策の必要性はますます高まると思われます。
高品質のデータは常に最重要であるが、LLM技術の進歩に伴い、堅牢なデータ・インフラに投資している企業は明確な優位性を享受することになります。さらに、変化し続けるデジタル環境において、セキュリティは依然として揺るぎない懸念事項です。ゼロ・トラストやデータ・セキュリティといったプラクティスは、今後もシステムを保護するために不可欠なものです。
デジタル環境の敵対性が高まるにつれ、強固なセキュリティ対策の必要性はますます高まると思われます。
当サイトの内容、テキスト、画像等の転載・転記・使用する場合は問い合わせよりご連絡下さい。
エンジニアによるコラムやIDグループからのお知らせなどを
メルマガでお届けしています。



