
関連するソリューション

業務改革
AI
グローバルイノベーションセンター
フェロー 黒住 好忠
みなさまこんにちは。株式会社インフォメーション・ディベロプメントのフェロー兼、株式会社ID AI Factory 代表取締役の黒住です。
今回は、大規模言語モデル(LLM: Large Language Model)やRAGの広がりにともない、昨年あたりから急速に伸びてきている「ベクターストア(Vector Store)」について解説したいと思います。
今後、Vector Storeの需要は更に伸びてくると思われるため、今のうちにVector Storeについて理解しておきましょう。なお、LLMやRAGについて知りたい場合は、前回私が書いた
『生成AIのトレンド「LLM+RAG」を解説 』も参照いただければと思います。
Vector Storeとは?
はじめてVector Storeという言葉を耳にする方もいらっしゃると思いますので、まずは「Vector Storeが何なのか?」という点についてお話ししたいと思います。
Vector Storeを簡単に言うと、「数値を入れておける入れ物」です。
もう少し厳密に言うと、単なる数値ではなく「複数個の数値のセット」を入れられるようになっています。例えば、[1, 2]というような形で、2つの値のセットを登録したり、[1, 1, 2, 3, 5, 8, 13]というような7個の値のセットを登録したり…という具合です。
このような複数個の数値のセットを、専門用語で「ベクトルデータ」と言います。ベクトルという言葉を聞くと身構えてしまう方も多いかもしれませんが、実は何も難しいことはなく、「複数の数がセット」になっていれば、それがベクトルデータです。
例:複数の数値をセットにしたもの=ベクトルデータ
- 1 → 単なる1つの数値(1つだけの数を専門用語で「スカラー値」と言います)
- 3.14 → 単なる1つの数値(つまり、スカラー値)
- [0, 1] → 0と1という2つの値をセットにしたもの → ベクトルデータ
- [1, 2, 3, 4, 5] → 5つの値をセットにしたもの → ベクトルデータ
- [0, 0, -1, 0, 1, 0, 1, 0, -1, 1] → 10個の値をセットにしたもの → ベクトルデータ
文章や画像、音声をベクトルに変換
ベクトルデータ(複数個の数値の集まり)を登録して、何がうれしいのか?・・・と疑問に思われるかもしれませんが、その裏には、最近のAIの進化が大きく関わっています。
私たちが普段慣れ親しんでいる「文章」や「画像」や「音声」などのデータは、表現方法も、コンピューター上での管理方法も全く違っています。文章であれば、メモ帳やWordのようなワープロソフトで編集して、単語で文字検索などの操作ができますが、画像や音声は単語では検索できません。似たような画像を探すために、たくさんの画像を目で見ながら探しているケースも多いのではないでしょうか。
ところが、最近のAIの進化で、文章や画像、音声など、形式が全く異なるデータも「全てベクトルデータ(数値の集まり)に変換」できるようになりました。その結果、文章や画像や音声といったデータに対しても「ベクトルデータ」だけを見て、同じような方法で似ている文章・画像・音声などを検索できるようになったのです。
このような背景もあり、以前にも増して「ベクトルデータ」の重要性が高まってきています。
参考までに、「昔々、あるところにおじいさんとおばあさんが住んでいました」という文章をAIモデルを使ってベクトル化すると、次のようなベクトルデータ(数値の集まり)に変換されます。データが多すぎるので省略していますが、数千個の数値の集まりで表現されます。
なぜ、Vector Storeが必要なのか
ベクトルデータの重要性が高まってきた背景は上記の通りなのですが、ベクトルデータ(複数の数値が集まったデータ)を登録するだけであれば、従来から存在するデータベースで十分です。つまり、Excelの表形式のような従来の方法で値を管理しても、以下のように「ベクトルデータを登録しておくことは可能」になります。
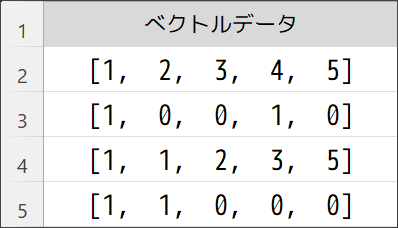
ベクトルデータの登録だけであれば従来の方法でも対応できる中、近年になってVector Storeが急速に注目されるようになったのには、大きな理由があります。
従来型の管理方法では、データを利用する時に以下のような問題が発生します。
類似するデータの検索が難しい
ベクトルデータになっていれば、文章や画像、音声なども同じ方法で類似情報を検索できるとお話ししました。しかし、ベクトルデータだけを見ても、それぞれのデータが「似ているかどうか」の判断が難しくなります。
例えば、 [1,0,0,1,0] と [1,1,0,0,0] の2つのベクトルデータは、似ているのかどうか?似ているとすれば、どのくらい似ているのか?・・・など、単純には判断できません。
ところが、Vector Storeであれば、最初から「ベクトル同士の類似度」を計算できるケースがほとんどです。つまり、ベクトルデータを登録するだけで、似ているかどうかの判断はVector Storeが全て計算してくれるようになります。
ベクトル同士の計算に時間がかかる
Vector Storeを使えば、ベクトル同士の計算は自動で行えるようになりますが、Vector Storeを使わなくても、数学の知識さえあれば「ベクトル同士の類似度」は、自分で計算させることも可能です。
ただし、この場合でも「計算に膨大な時間がかかる」という問題が立ちはだかります。例えば、10,000枚の写真をベクトル化して登録していたとすると、登録されているベクトルデータの数も10,000個になります。この写真の中から、手元にある写真と一番似ている写真を検索しようとすると、10,000枚ある写真のうち、どの写真が一番似ているかを判断するために、10,000個のベクトルデータ全てに対して類似度の計算を行う必要があります。そうすると、データ件数に応じて計算処理も膨大になり、実用に耐えないほどの計算時間になります。
この問題についても、Vector Storeでは「効率よく計算できる仕組み」が組み込まれているため、データ数が増えても、非常に高速に類似度計算が行えます。
これらの、実際にベクトルデータを「利用する時の利便性」が、Vector Storeが利用される大きな理由のひとつになっています。
どうやって類似度を判断しているのか
類似度を計算する方法にはいくつか種類があるのですが、ここでは、利用頻度の高い2つの方法について紹介します。実際の数式にすると難しくなるので、おおよそのイメージで説明します。
なお、これらの計算アルゴリズムは、ほとんどのVector Storeで利用できます。
コサイン類似度
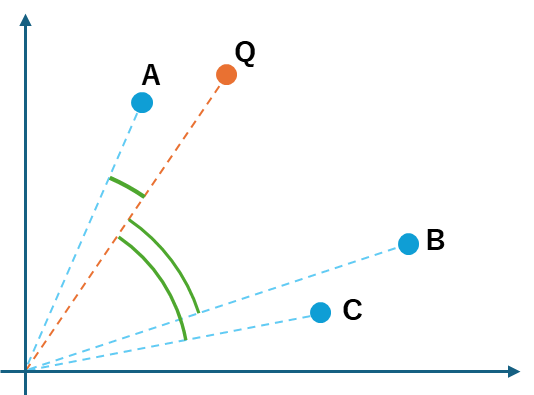
LLMでRAGの仕組みを実現する際に良く利用される手法です。難しそうな名前が付いていますが、考え方は非常にシンプルです。ベクトルデータは、「複数の数値の集まり」なので、各ベクトルは「高次元上の1つの点」として表すことができます。話が難しくなるので、ここでは分かりやすく、各ベクトルを「2つの数値のセット」で表現した例で説明します。(A=[1,2]、 B=[3,1]のような2つの値のセットなので、2次元上のグラフで図示できます)
それぞれ、A, B, Cの3つのベクトル(点で表現)と、検索したいベクトル値Qがあった場合、コサイン類似度では、各ベクトル間の「角度」で類似度を判断しています。下の例では、ベクトルQの角度(方向)に一番近いのはベクトルAになります。続いて、ベクトルB、Cという順で角度が近いため、コサイン類似度で見ると「ベクトルQに近い順に、ベクトルA、B、C」という結果になります。
このように「角度が近いかどうか」で判断するのが「コサイン類似度」の仕組みです。
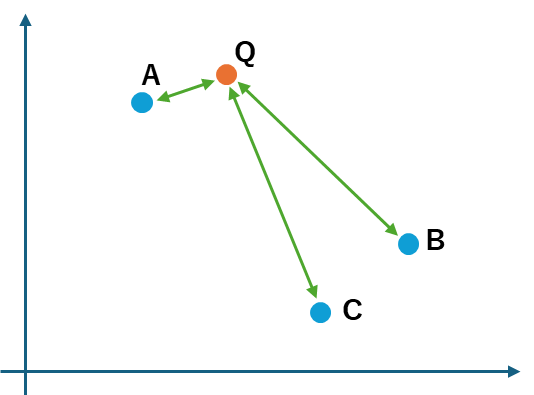
ユークリッド距離
ベクトル間の距離によって類似度を判定する手法もあります。距離にも、ユークリッド距離やマンハッタン距離など、いくつかの種類があるのですが、分かりやすいのは「ユークリッド距離」です。こちらも難しそうな名前ですが、要は「点を直線で結んだときの距離(長さ)」がユークリッド距離です。ユークリッド距離で類似度を判断した場合も、ベクトルQに最も直線距離が近いのはベクトルA、続いてベクトルB、Cがほぼ同じ距離で近い・・・と判断されます。
各ベクトル同士の「角度や距離」で本当に類似度が判断できるのか?…と疑問に思うかもしれませんが、AIモデルを使って文章や画像、音声をベクトル化すると、「類似する情報は、だいたい近くに集まる」という特徴があるため、この仕組みで類似度の判断ができます。
例えば、文章をAIモデルでベクトル化した場合、「犬」や「猫」などはベクトル空間上で近い位置になり、「ロケット」などは「犬や猫」と遠く離れた位置に配置されます。
Vector Storeの活用例
AIモデルとVector Storeを組み合わせることで、文章や画像、音声をベクトル化して類似度計算が可能になり、例えば以下のような用途で活用できるようになります。- 情報の検索:類似する文章や画像、音声などを検索できるようになります。文章も「文章全体の意味合い」で判断できるため、細かい表現が違っていたとしても検索が可能になります。(セマンティックサーチと呼ばれることもあります)
- 異常検知:正常なデータとの類似度などを用いて、異常検知などに応用することも可能です。
まとめ
RAGをはじめとして、Vector Storeは急速に注目されるようになってきた技術です。AI技術の進化と共に、ベクターデータを活用して、従来のデータベースでは実現が難しかった処理も実現できるように変わりつつあります。現時点でオープンソースから商用サービスに至るまで、数多くのVector Store製品が存在しています。標準でサポートされている機能も千差万別で、全ての製品で全く同じことができるわけではありません。また、登録できるベクターデータの次元数(1つのベクトルに含める数値データの個数)やパフォーマンスにも違いがあります。
今後も、Vector Storeは大きく進化していくと思われるため、引き続き目が離せませんね。
それではまた、次回のコラムでお会いしましょう。
当サイトの内容、テキスト、画像等の転載・転記・使用する場合は問い合わせよりご連絡下さい。
エンジニアによるコラムやIDグループからのお知らせなどを
メルマガでお届けしています。



