
関連するソリューション

業務改革
AI
エバンジェリスト・フェロー
玉越 元啓
Cutting-Edge Technology Department /
Motohiro Tamakoshi
今回は、「ディープラーニングでつくるマスク着用判定AI」をテーマでお送りします。
■ディープラーニングでつくるマスク着用判定AI
■三人よれば文殊の知恵
■AIの見える化
ディープラーニングでつくるマスク着用判定AI
ディープラーニングの技術を活用してマスクの着用を判定するAIをつくりました。いくつかのアイデアのうち、次の3つのアプローチを並行して進めてみました。これは、同じ目的であっても様々な手法があることを感じていただきたいからです。
①Alexnet(アレックスネット)のファインチューニング
②顔検出→マスク判定
③オープンソース(TeachableMachine)の活用
AIの学習用に、マスクありの顔画像を50枚・マスクなしの顔画像を50枚・マスクのみの画像を50枚使用しています。学習用の画像としては、少な目になっています。結果の判定には、学習用の画像とは別の画像を用意してテストしています。AIによってきちんと判定できる場合とできない場合がありましたが、それぞれの結果とポイントについてお話します。
①Alexnetのファインチューニング
まずは、テスト結果からご覧ください。なかなかバランスのよい判定ができています。
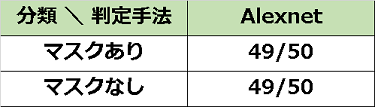
表の見方は次のとおりです。
・マスクあり・・・マスクをした画像を判定した結果
・マスクなし・・・マスクをしていない画像を判定した結果
・結果の表記は、正しく判定できた枚数/テストした枚数です。「49/50」は、50枚のうち49枚正しく判定できたことになります。
Alexnetとは、様々な画像を1,000の異なるクラスに分類する「ImageNet LSVRC-2010」というコンテストのために考案された、ディープラーニングの代表的なモデルです(※畳み込みニューラルネットワークと呼ばれる手法を採用しています)。クラス分類向けに学習したAIを基にして、他の用途向けに調整することをファインチューニングといいます。
※畳み込みニューラルネットワークとは、データから特徴を抽出する機能(畳み込み層とプーリング層と呼ばれます)と、抽出された特徴から判定をする機能(全結合層と呼ばれます)で構成されています。コンテスト用につくられたAlexnetのままではマスクをしている顔としていない顔の判定はできないので、画像の特徴を抽出する機能はそのまま流用し、最後に分類を行う部分を修正して、マスクをしているかどうか判定できるようにしました。
Alexnetの構成
Alexnetの詳細は、以下の論文をご覧ください。
※外部サイト:ImageNetClassificationwithDeepConvolutional NeuralNetworks
②顔検出→マスク判定
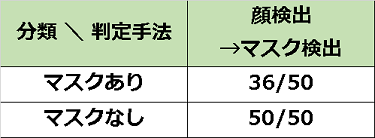
精度としては、マスクありとマスクなしで大きく差がでています。
こちらの方法は、まずは画像から顔を検出し、顔を検出できたらその範囲に「マスクがあるか?」を判定しています。顔の検出にはopencvを利用し、マスクの検出には専用のAIモデルを作成しました。このマスク判定AIモデルの学習には、マスクの画像そのものを使用し、人がマスクを着用している画像は使用していません。また、マスクをした顔を、顔として認識できないケースがありました。顔の検出の精度が上がれば、マスクを判定できる精度も上がると思われます。
マスクの有無判定に利用したマスクの一部

当初は、顔を検出後、顔の構成(目、鼻、口、輪郭など)を分析し、口が隠れているものを「マスクしている」判定にしようと進めていました。実装してみると、マスクをして鼻や口が見えない状態であっても鼻や口の位置を推測できてしまったため、このアプローチは断念しました。
こちらが開発途中で取得した画像です。青い点は顔の構成を表しており、緑の枠は検出したマスクを表しています。

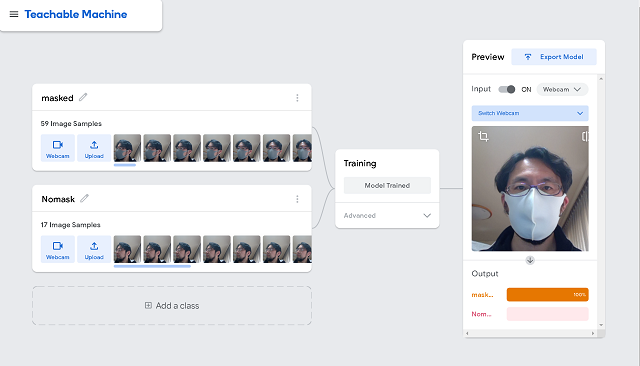
③オープンソース(TeachableMachine)の活用
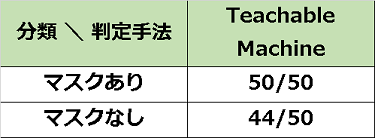
数値だけをみると、全体的な精度は、それなりに良いと思えます。
これを業務的な観点から考えてみます。マスクの有無を判定したい場面の多くは、「マスクをしていない人を見つける」ことではないでしょうか。マスクをしていないにも関わらずマスクをしていると判定されている数が多く、このままでは問題がありそうです。
TeachableMachineについては、同僚のコラム【エバンジェリスト・ボイス】モデル作成及び検証に最適なTeachable Machineをご紹介 を参考にしました。AIの学習はブラウザ上で行い、学習した結果のモデルをダウンロードして組み込んでいます。注意点としては、ダウンロードしたファイルを利用するには、pythonのライブラリであるTensorflowのバージョンを、TeachableMachineの環境とそろえる必要があります。
コラム執筆時点(2021/3/24)では、TensorFlow 2.4.1 が利用されています。私はこの違いに気が付かず、てこずりました。
TeachableMachineを使用している様子
三人寄れば文殊の知恵
AIの精度を上げるためのアプローチはいくつかありますが、ここでは複数手法による多数決を紹介します。
今回作成したAIを組み合わせて、3つのうち2つ以上のAIが出した判定を最終的な決定としたときの結果は下のようになりました。

それぞれ違うアプローチで作成したAIのため、正解の判定や間違え方にバラつきがあり、多数決をとると期待した成果が現れています。
3つのAIによる多数決をとると、それぞれの精度が80%の場合は、多数決による精度は89.6%まであがります。それぞれの精度が90%の場合は、97.2%になります。こうした計算結果だけを見ても、有効性を感じていただけると思います。
AIの見える化
AIの判定基準については、長い間ブラックボックス化していました。現在は、「AIの判定結果を人が理解しやすくするため」の研究がすすめられています。画像のどこに着目して判定したかを視覚化する手法がその一つです。今回のマスク有無の判定結果について、どの部分が判定結果に大きな影響を与えたかを計算し、その結果を元の画像に重ね合わせてみました。
マスクありと判定された画像の例

マスクなしと判定された画像の例

画像を見ると、単に判定結果が出るだけよりも、AIが何を考えているかが分かりやすいのではないでしょうか。複数手法を組み合わせることで、画像のどこに着目してマスク有無を判定したか、人の顔の構成の検出結果、マスクを検知した位置、などを表示することができます。大量のデータのなかから、人が判断すべきデータをAIが抽出するだけでなく、人が見たときの判断材料を提供できるところまでAIの技術は発展しています。
まとめ
・同じ目的のAIでも、様々な手法でつくることができます。
・複数のAIを組み合わせて全体の精度をあげるアプローチがあります。
・AIの判定結果を人に分かりやすく表現する技術も発展しています。当サイトの内容、テキスト、画像等の転載・転記・使用する場合は問い合わせよりご連絡下さい。
エバンジェリストによるコラムやセミナー情報、
IDグループからのお知らせなどをメルマガでお届けしています。



