
関連するソリューション

業務改革
AI
プリンシパルフェロー 黒住 好忠
AIを活用して社内の独自データに基づいた回答を得たい。そういったニーズへの対応として、現在もっとも広く使われているのが「RAG(Retrieval-Augmented Generation)」と呼ばれる仕組みです。一言で表すなら、社内の文書データをAIが参照できるようにして、回答の精度を高める技術のことです。
ただ、実際にRAGを導入してみると「なんだかズレた回答が返ってくる」「欲しい情報がうまく引き出せない」といった経験をされた方も少なくないのではないでしょうか。
今回は、そのRAGの課題を出発点に、かつてソフトウェア開発の世界で起きた「発想の転換」と照らし合わせながら、AIのデータ活用における一つのアーキテクチャのアイデアをご紹介したいと思います。確立されたトレンドというよりも、「こういう考え方もあるのではないか」という視点をお伝えするものです。ぜひ一緒に考えていただければと思います。
RAGの仕組みと、その弱点
まずは、RAGが抱える課題に焦点を当てて、その仕組みを簡単に振り返ります。詳細は私が以前に執筆した『生成AIのトレンド「LLM+RAG」を解説』でご説明していますので、ここではポイントを絞って見ていきましょう。データの「断片化」という問題
RAGでは、社内文書や規定などの独自データをAIに活用させるために、まず、そのデータを「チャンク」と呼ばれる小さな断片に分割し、データベースに保存します。AIへの質問が来ると、その質問内容と「なんとなく似ている」断片をデータベースの中から自動的に選び出し、AIに渡して回答を生成させます。これがRAGの基本的な流れです。しかし、ここで問題が生じます。例えば、社内規定の文書を「文章の内容や区切りに関係なく、一定の文字数ごとにハサミで切り刻む」場面を想像してみてください。文章の意味や段落の区切りは一切無視して、機械的に同じ長さで切っていくイメージです。
その結果、例えば「有給休暇は、入社から6ヶ月以上経過し、かつ所定労働日数の8割以上を出勤した社員に対し」というところで一枚目が終わり、残りの「年間10日間付与されます。ただし、パートタイム勤務者については別途……」から二枚目が始まる、という状態になります。つまり、一枚目を見ても「何が付与されるのか」がわからず、二枚目を見ても「誰に対する話なのか」がわからない。中途半端な断片の集まりになってしまうのです。
「似ている」だけでは正確に選べない
さらに、断片を選び出す際にも課題があります。「なんとなく似ている」という基準で機械的に判断するため、例えば「解約」について質問したとき、解約手続きとは全く関係のない別の規定の中に「解約」という言葉がたまたま含まれていれば、そちらの断片を持ってきてしまうこともあります。前後の文脈が失われた断片をベースにしているため、AIはその情報が本当に質問と関係があるかどうかを正確に判断することが難しくなります。その結果、的外れな回答につながってしまう。これがRAGの精度課題の一因なのです。
では、この「断片化」と「文脈の喪失」という課題を、どのように乗り越えればよいのでしょうか。実は、ソフトウェア開発の世界で過去に起きた、ある発想の転換にヒントがあります。

プログラミングの世界で起きた「発想の転換」
ここでは、RAGの課題である「データの扱い」に焦点を当て、ソフトウェア開発の世界で同様の課題がどのように解決されてきたのかを見ていきましょう。「データはデータ、処理は処理」だった時代
かつてのプログラムは、「データはデータ、処理は処理」と完全に分離されているスタイルが主流でした。顧客情報・在庫情報・売上データといったデータは一箇所にまとめて置かれており、それぞれの処理プログラムが、必要なときに直接そのデータを読みに行ったり、書き込んだりしていました。プログラムとデータの間に「担当」という概念はなく、どのプログラムもデータに直接アクセスできる構造です。これはRAGの発想、つまり大量のデータを一箇所に集めて管理し、必要なときに直接取りに行くという考え方とも共通する部分があるのではないでしょうか。
オブジェクト指向という「発想の転換」
そこに大きな転換をもたらしたのが「オブジェクト指向」という考え方です。身近な例で考えてみましょう。大きな会社の事務所を想像してください。昔は、すべての書類(データ)が一箇所の棚にまとまっており、誰もが直接その棚にアクセスして書類を取り出していました。ところがある時、「書類はその担当者自身が持って管理する」という考え方が生まれます。
顧客情報は顧客担当者が、在庫情報は在庫担当者が、それぞれ自分の引き出しに持って管理する。何か知りたければ棚に直接行くのではなく、その情報を持つ担当者に「教えてください」と声をかける。そして担当者が自分の知識と情報をもとに答えてくれる。こういうスタイルに変わったのです。
この考え方には、2つの重要な概念が含まれています。
- カプセル化:担当者がデータと知識をひとまとめに持ち、外部からは直接データに触れさせない仕組みのことです。情報の管理責任が明確になるという点がポイントです。
- メッセージによるやりとり:担当者への「声かけ」にあたる概念です。担当者同士が問いかけを通じてやりとりすることで、データを直接操作することなく、必要な情報を引き出すことができます。
この発想を中心に据えたのが「オブジェクト指向」というアプローチです。まさに、ソフトウェア開発の世界を大きく変えたパラダイムシフトでした。
では、この「カプセル化」と「メッセージによるやりとり」という発想を、AIのデータ活用にも取り入れることはできないのでしょうか。

AIのデータ活用にも「カプセル化」の発想を
ここからが今回の本題です。「カプセル化」と「メッセージによるやりとり」という発想を、AIのデータ活用にそのまま取り入れてみてはどうでしょうか。それがこのアイデアの出発点です。「担当エージェント」がデータを丸ごと持つ
RAGの課題の根本は、「細切れになったデータがバラバラに並んでいて、そこから必要な情報を探し出す」という構造にあります。人間で言えば、担当者のいない共有棚を全員が探し回っているようなものでしょう。そこで提案したいのが、オブジェクト指向の「カプセル化」と同じ発想をAIのデータ活用に取り入れることです。具体的には、データを細かく切り刻んで一元管理するのではなく、「ある程度まとまった情報の単位ごとに、その内容を専門に担当するAIエージェントを用意する」というアプローチになります。
例えば、社内規定が100件あるとします。RAGではこれらを全て細かく切り刻んで一つのデータベースに入れますが、今回のアプローチでは「規定1件の内容をまるごと担当するAIエージェントを1つ用意する」という形になります(AIエージェントの仕組みについては、以前に投稿した『AIエージェントの仕組みを徹底解説~なぜ「自分で考えて動くAI」が実現できたのか~』をご覧ください)。そのエージェントは、担当する規定の全文を文脈ごと理解しています。まるでその規定のスペシャリストが社内に在籍しているようなイメージです。
エージェント同士の「会話」で情報を引き出す
このアーキテクチャでもう一つ重要なのが、エージェント同士のやりとりの仕方です。RAGでは、データベースから断片を「直接取ってくる」という構造でした。一方このアプローチでは、あるエージェントが別のエージェントに対して「○○について教えてください」と自然言語で問いかけ、担当エージェントが自分の持つ情報をもとに回答するという「会話」の形でやりとりが行われます。こうした複数のエージェントが連携する仕組みは「マルチエージェント」とも呼ばれています。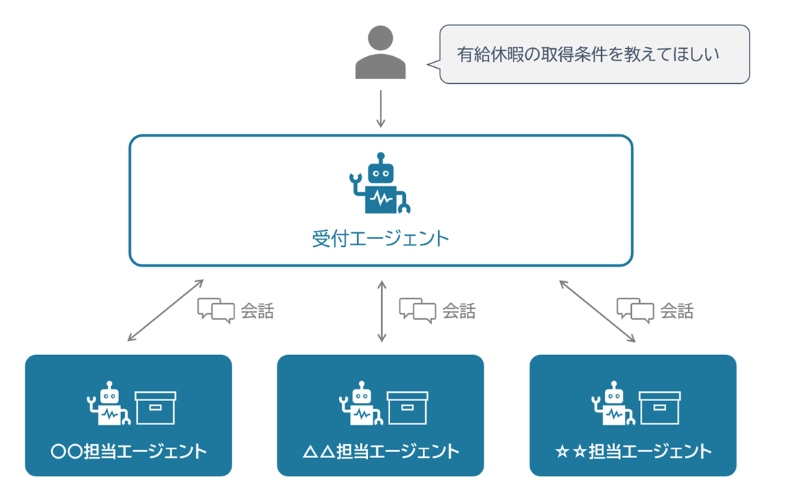
図:情報をカプセル化したエージェント同士が会話をする構成
具体的な流れを見てみましょう。従業員からの問い合わせを受け付ける「受付エージェント」が「有給休暇の取得条件を教えてほしい」という質問を受けたとします。受付エージェントは自分では回答せず、有給休暇規定を担当するエージェントに「有給休暇の取得条件は何ですか?」と問いかけます。担当エージェントは、規定の全文を文脈ごと把握したうえで「入社から6ヶ月以上経過し、所定労働日数の8割以上を出勤した社員に対して年間10日間付与されます」と正確に回答します。受付エージェントはその回答をもとに従業員への返答を組み立てる、といった具合です。
この「問いかけと回答のやりとり」は、オブジェクト指向の「メッセージによるやりとり」と非常によく似ています。データを直接取りに行くのではなく、そのデータを担当するエージェントに「聞く」という構造にすることで、情報の文脈が保たれたまま処理が進むのです。
RAGとの本質的な違い
ここで、RAGとこのアプローチの本質的な違いを整理してみましょう。- RAG: 断片化されたデータの中から、質問と似た断片を探し出して回答を組み立てます。しかし、断片化によって文脈が失われるため、精度の保持に限界があります。
- カプセル化アプローチ:その情報全体を理解しているエージェントに直接聞くことで回答を得ます。断片化が起きないため、文脈の損失を防ぐことができます。
人間に例えるなら、「バラバラに切り刻まれた紙切れを探し回る」のではなく、「その分野のスペシャリストに直接質問する」という違いです。
細切れの断片をかき集めて回答を作るのではなく、「その情報を担当するエージェントに問いかける」という構造にすることで、情報の文脈が保たれ、精度の向上が期待できます。それが、このアーキテクチャに可能性を感じている理由なのです。

メリット・デメリット
もちろん、この考え方にはメリットだけでなく、デメリットや課題もあります。メリット
- 文脈の保持:情報の文脈が保たれるため、チャンクへの断片化による精度低下を防ぎやすくなります。
- 責任範囲の明確さ:「この情報はこのエージェントに聞く」という担当が明確になることで、回答の根拠を追いやすくなります。
- 更新の容易さ: エージェントごとに独立しているため、特定のデータを更新・差し替えたい場合も対象エージェントだけを変更すれば済みます。
デメリット・課題
- コストの増加:エージェント同士が会話を重ねながら処理を進めるため、AI(LLM)の利用回数が増え、運用コストが上がる可能性があります。
- 設計・管理の複雑さ:扱うデータの数だけエージェントが必要になるため、全体の設計・管理が複雑になるでしょう。
これらのトレードオフを踏まえると、「どちらかのアプローチが絶対的に優れている」という話ではなく、データの性質・求める精度・コスト・リアルタイム性の要件によって使い分けることが重要です。
例えば、シンプルな情報検索や大量のデータを横断的に扱う場合はRAGが適している場面も多いでしょう。一方で、精度が特に求められる専門的な情報や、文脈の保持が重要な業務ドメインでは、今回ご紹介したエージェントによるカプセル化の発想が有効になるかもしれません。AIのアーキテクチャにも、用途に合わせた「適材適所」の視点がますます重要になってきていると感じています。

まとめ
今回は、RAGの課題を出発点に、ソフトウェア開発の世界で起きた「オブジェクト指向」という発想の転換を手がかりとして、AIのデータ活用における一つのアーキテクチャのアイデアをご紹介しました。お伝えしたかったポイントを簡潔に整理します。
- RAGの課題:データを断片化して管理するため、文脈が失われ、的外れな回答につながることがあるという点です。
- オブジェクト指向のヒント:「カプセル化」と「メッセージによるやりとり」という考え方により、データと処理の責任を担当者に集約するという発想です。
- エージェントによるカプセル化:データを丸ごと担当するAIエージェントを用意し、エージェント同士の「会話」によって情報を引き出すことで、文脈を保ったまま精度の高い回答が得られる可能性があります。
- 適材適所の視点: コストや処理時間とのトレードオフがあるため、データの性質や要件に合わせて、RAGとカプセル化アプローチを使い分けることが大切です。
これは一つの考え方の提案であり、今後の技術の進展によってさらに洗練されていくはずです。皆さまの現場でAIの活用方法を考える際の参考にしていただければと思います。
AIに関してお困りごとがあれば
今回ご紹介したRAGやエージェントによるカプセル化のように、AIのデータ活用にはさまざまなアプローチがあります。「自社のデータにはどのアーキテクチャが合うのだろう」「RAGの精度を改善したいが、どこから手をつければよいのか」と感じている方もいらっしゃるのではないでしょうか。弊社では、こうしたAI活用に関するお悩みに幅広くお応えしております。例えば、「AIエージェントを導入してみたい」「そもそもAIで何ができるのか整理したい」といったちょっとした相談から始められるアドバイザリーコンサルサービスをご用意しています。
さらに、これからAI活用を始めたい方に向けた研修サービスも提供しています。ChatGPTのようなサービスを使いこなすための「AIリテラシー研修」や、Difyのようなノーコードツールで業務に合わせたカスタムAIを作れるようになる「Dify研修」など、段階に合わせたプログラムで皆さまのAI活用を支援しています。
ご興味がありましたら、ぜひお気軽にご相談ください。
それではまた、次回のコラムでお会いしましょう。
当サイトの内容、テキスト、画像等の転載・転記・使用する場合は問い合わせよりご連絡下さい。
エンジニアによるコラムやIDグループからのお知らせなどを
メルマガでお届けしています。



