
関連するソリューション

業務改革
AI
先端技術部
エバンジェリスト 黒住 好忠
こんにちは。先端技術部、エバンジェリストの黒住です。
私事ですが、少し前に、長年使っていたドライヤーが故障しました。家族は、1ヶ月くらい前から少し音が変だと感じていたようですが、私は故障する直前まで気がつきませんでした。そこで今回は、音の違いを聞き分けるAIを作成し、私(人間)とAI、どちらが正確に音を聞き分けられるか勝負してみたいと思います。
全体の概要
今回は、微妙に異なる2種類の音を用意し、その音を聞き分けるAIをTensorFlowを使って作成します。そして、ランダムに用意した100個の音を、私とAI、どちらが正確に予測できるか検証してみます。
聞き分ける音の準備
聞き比べる音として「スネアドラムの音」を選択しました。スネアドラムはスティックで叩く場所によって音が変化するため、微妙な音の聞き分けには最適です。今回は、スネアドラムの「中央部分」と「周辺部分」を叩いたときの音を、聞き分ける対象とします。
実際にドラムの音をレコーディングしても良いのですが、我が家にドラムは無いので、DAWなどの音楽制作で使われる「ドラム音源」を利用します。ドラム音源にもいくつかの種類が存在するのですが、今回は、ドラムの音を計算によってシミュレートする「モデリング音源」を利用します。実際の音をレコーディングした「サンプリング音源」も存在しますが、こちらは、音のバリエーションが少なくなるため利用しません。
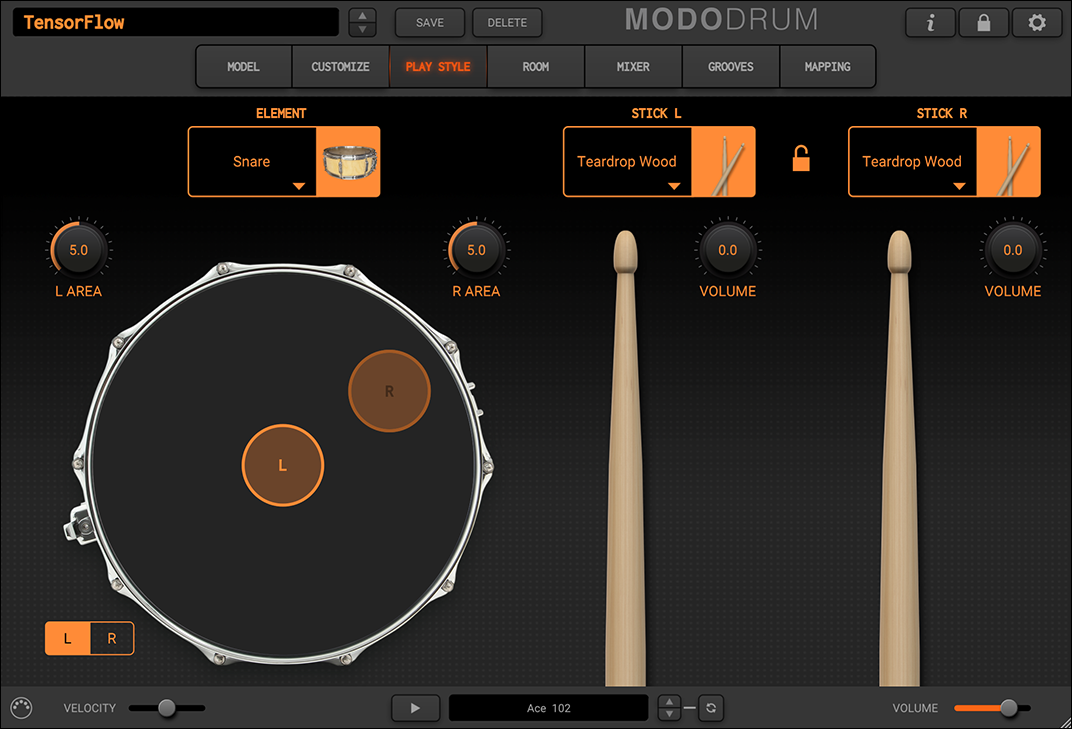
以下は、今回利用するドラム音源「IK Multimedia MODO DRUM」の画面です。左側にスネアドラムを上から見た図があり、オレンジ色の円で「L、R」と書かれている部分が、実際のスティックで叩くエリアになります。左スティックは中央部分、右スティックは周辺部分を叩くように設定しています。打点は円の範囲内でランダムにずれるので、同じ中央/周辺部分であっても音にバラツキが出るようにしています。
処理の構成
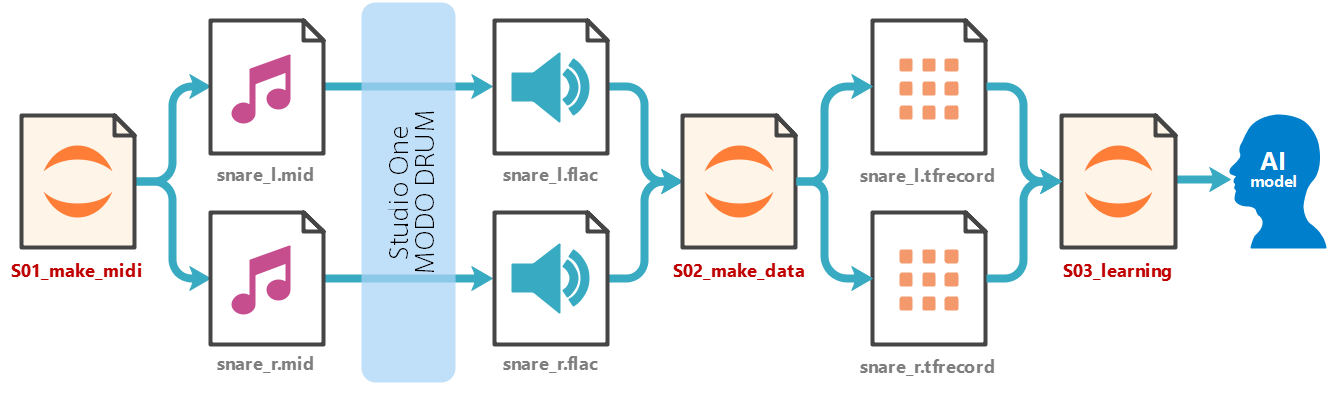
大きく「AIを作成する部分」と「聞き分け対決」を行う2部構成に分かれます。
まず「AIを作成する部分」は以下のような流れで、AI作成に使用する音声データを作成した後、TensorFlowで処理しやすい形式に変換し、実際のAIモデルを作成しています。
図の赤字で記載している部分(例えば、S01_make_midi)が、実際にNotebookで記述しているPythonの処理になるので、それぞれの詳細については後述したいと思います。
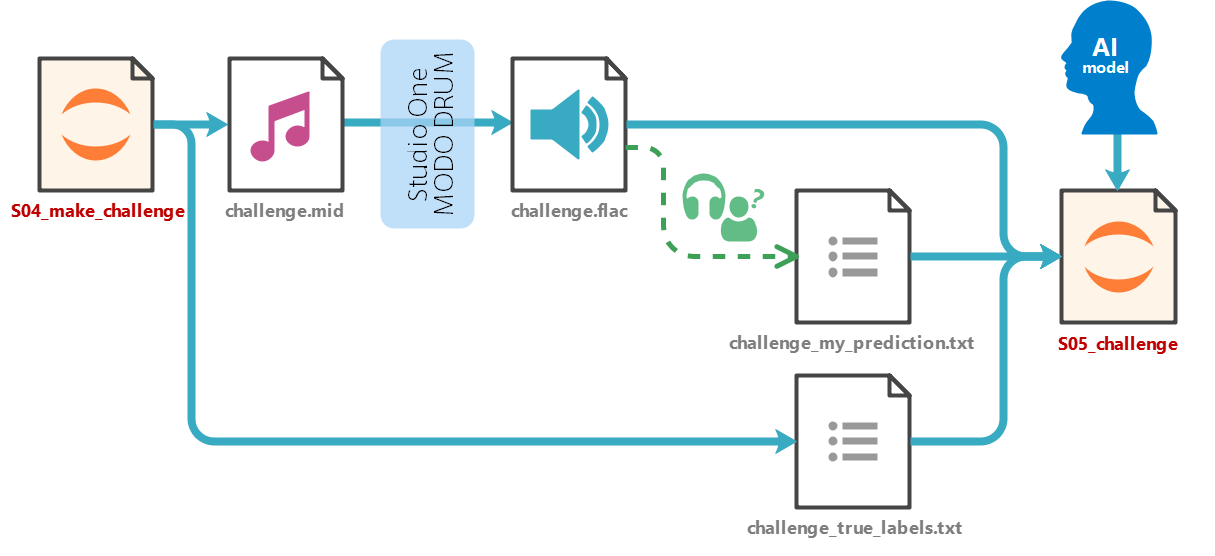
続いて「聞き分け対決」を行う部分の流れです。
聞き分け対決のための音声データ(100個のランダムなドラム音が録音されている)を作成し、私とAI、それぞれの予測結果の比較を行います。私の予想結果については、私が実際に音を聞いて正解だと思った内容を事前にテキストファイルで作成しています。
では、各処理の詳細な内容を見ていきましょう。
AIを作成する部分(S01~S03)
S01_make_midi:教育用の音声データ作成
まずは、AIモデルの学習や検証で使用する音声データを作成します。
スネアドラムの「中央部分(左スティック)」と「周辺部分(右スティック)」ごとに、叩く強さ(ベロシティ)を変えながら、ひたすらドラムを叩くだけのMIDIデータを作成し、それをStudio One上のMODO DRUM経由で音声データに変換します。このとき、音声データを後で抽出しやすいように、テンポは120BPMとしています。120BPMの場合、楽譜で言う1小節の長さが2秒になるので、2秒間隔で音声データを抽出すれば、簡単に1小節単位のデータを抽出できます。
また、音声データは48kHz/24bitのflac形式で保存しています。wav形式もよく利用されますが、ファイルサイズが大きくなるので今回は可逆圧縮方式でもファイルサイズを押さえられるflacを使用しています。なお、aacやmp3のような非可逆圧縮方式は、音の情報が失われるので使用しません。
S02_make_data:音声データの事前処理
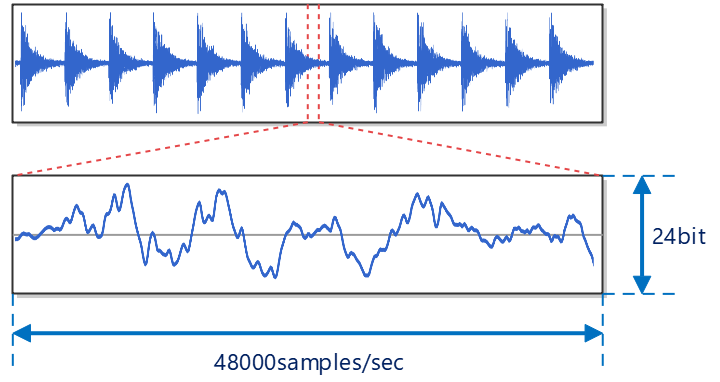
S01で作成した音声データは、48kHz/24bit形式のため、下図のように、1秒間に48,000回のサンプリングが行われており、各サンプルの値は24bitの精度で保持されています。
ちなみに、実際にレコーディングできる周波数はサンプリング回数の半分になるので、この場合は24kHzまでの音を記録できることになります。人間に聞こえる周波数帯域は20~20kHzくらいだと言われているので、人間に聞こえる範囲は全てカバーできていますね。
このままでは、1小節(120BPMなので2秒)ごとにドラムの音が鳴る、再生時間が約20分の音声データなので、処理には向いていません。そこで、今後の処理で扱いやすいように、各ドラムの音を1秒間の音声クリップデータとして抽出しています。また、ベロシティによって音のゲインも異なっているため、各クリップごとにサンプリング値が「プラスマイナス1.0」の範囲に収まるように、ノーマライズ処理を行い、TensorFlowで扱いやすいTFRecord形式に変換しています。
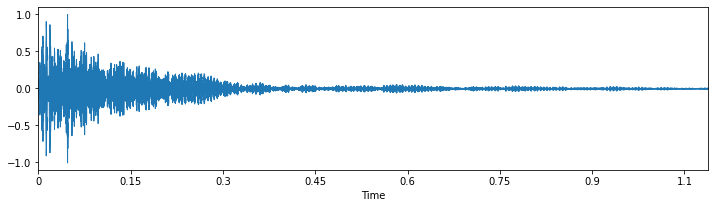
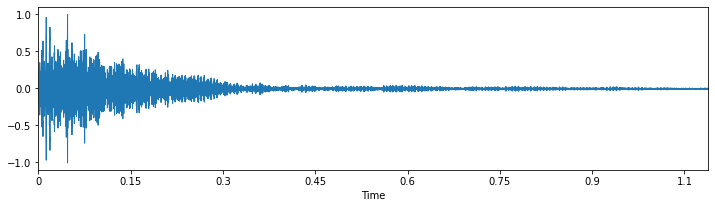
下図は、クリップ単位に分割してノーマライズ処理した、1クリップのサンプルです。上側がドラム中央部(左スティック)の音、下側がドラム周辺部(右スティック)の音になります。
ノーマライズ処理しているため、振幅幅がプラスマイナス1.0に収まっているのが分かると思います。ただ、波形画像だけを見ても、両方とも似たような形をしていて、これだけでは区別が付きませんね。
S03_learning:音声データの学習処理
AIモデルを作成し、準備したデータを使って学習を行います。
音声データのような時系列データの場合はRNNやLSTMなどを用いるか、音声データに限ってはスペクトログラム画像としてCNNを用いることが多い気がしますが、今回はTCN(Temporal Convolutional Network)を使用しました。TCNは時系列データに対して畳み込みを用いる手法で、並列処理が行えるためパフォーマンスが高いメリットもあります。また、汎用的なモデルに利用できるので、使い勝手もなかなか良さそうです。
準備した音声データの7割を学習データ、残りを検証データとしてTCNモデルを学習させた結果が以下の通りとなります。数エポックで結果は収束し、教育/検証用データともに、Accuracyは1.0に、Lossも限りなく0に近い値になってしまいました。
検証用データに対しても高い性能を示しているので過学習などではないのですが、今回は用意したデータがクリーンな状態(ノイズ等が入っていない)で、バリエーションも、思ったほど多くは無く、とても簡単に識別できてしまったようです。
とはいえ、これも一つの結果なので、このままAIモデルとの聞き分け対決に進んでいこうと思います。
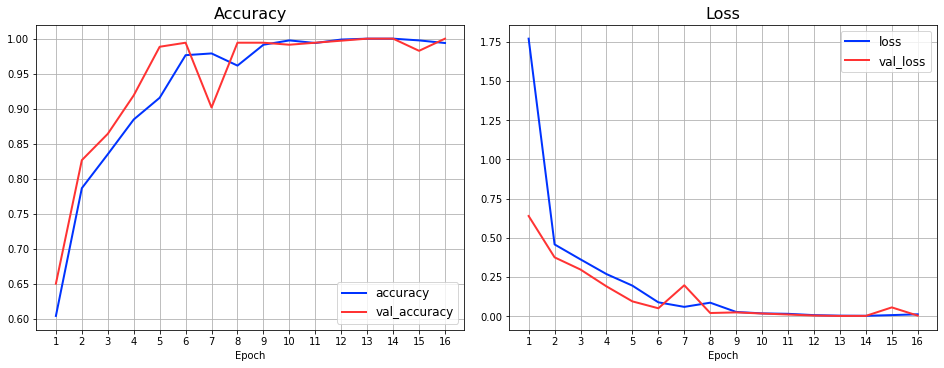
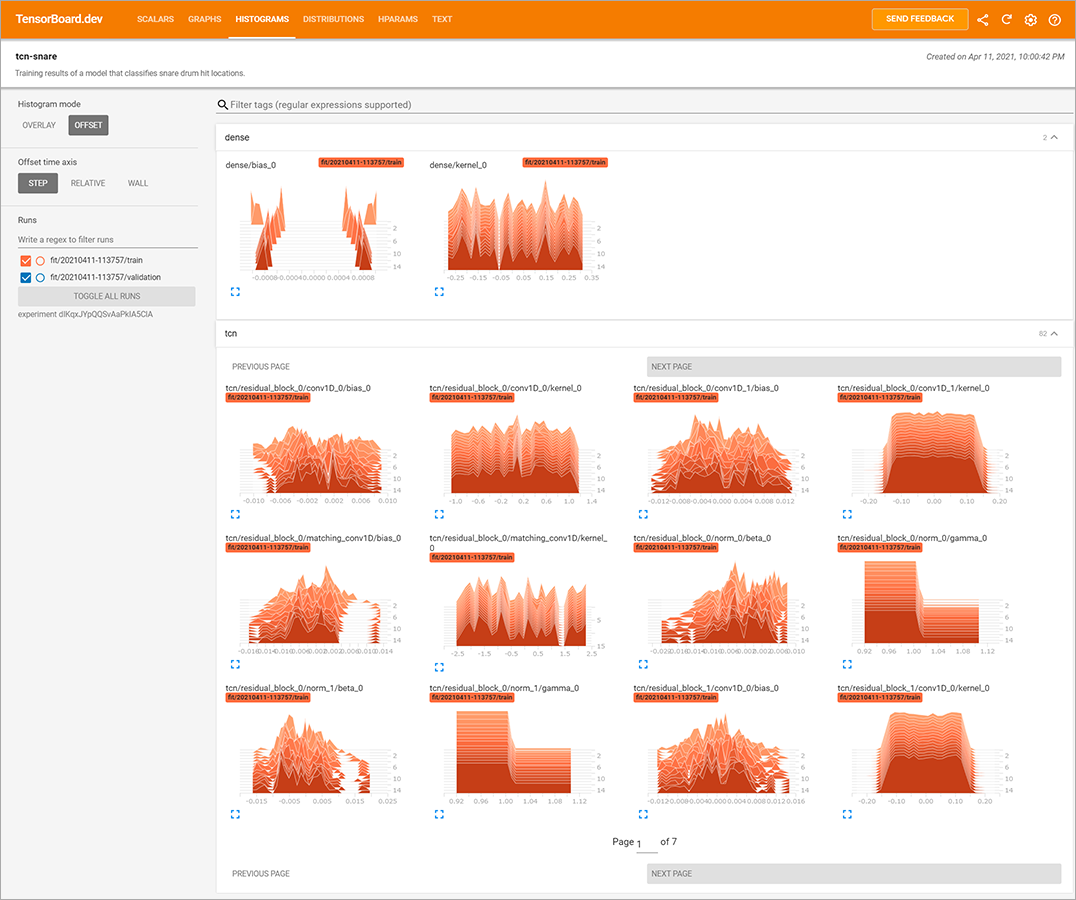
なお、エポック数を進めていくと性能が悪化していますが、TensorFlowの機能を使って、性能向上が見られなくなったタイミングで学習をストップさせ、最適な性能時点のウェイト値にリカバリするように設定しています。そのため、学習自体は16エポックまで実施してますが、実際に保存しているモデルは、13エポック時点の値になります。また、次のURLで、学習時のログをTensorBoard.devに公開しているので、必要に応じて参照してみてください。
聞き分け対決(S04~S05)
それでは、ランダムな100個の音に対して、聞き分け対決を行ってみたいと思います。
S04_make_challenge:チャレンジ用のデータ作成
まずは、聞き分け対決で利用する100個の音声データを作成します。
教育用データを作成するときと同じような手順で、左右スティックとベロシティをランダムにした100個のドラム音声を作成しました。機械的に答え合わせを行えるように、正解ラベルも同時に出力しています。
また、このタイミングで、私が実際に音を聞いて、正解だと思った内容(ドラム中央部の音なのか、周辺部の音なのか)を事前にテキストファイルで作成しています。半数以上は自信を持って聞き分けできたのですが、どちらか判断に迷う音もあったので、時間を空けて5回ほど予測してみました。
S05_challenge:聞き分け対決
いよいよ、私とAIの聞き分け対決の時がやってきました。
まず、上記で作成したAIの予測結果の答え合わせです。横軸がそれぞれ100個のドラムの音、縦軸が予想された確率(0.0~1.0)となっており、正解であれば緑、不正解なら赤色になります。グラフ上部に「R」と表記されているものがドラム周辺部(右スティック)、それ以外がドラム中央部(左スティック)の音になります。
結果を見ていただければ分かるのですが、AIの予測結果は全て正解です。しかも、全て限りなく100%に近い確率(自信)で何の迷いも無く正解しています。モデルを学習させたときにAccuracy=1.0となっていたので、この結果はなんとなく予想していましたが、思った通りの結果になりましたね。

続いて、私の予想結果です。私は時間を空けて5回予想したので、横軸がそれぞれ100個のドラムの音、縦は1~5回目までの予想結果に対する正誤結果になります。(私の予想結果に確率はありません)
見ていただけば分かるとおり、間違っている箇所がいくつか存在します。各回の正解率は、毎回ほぼ同じなのですが、5回全てを平均すると、私の正解率は「84%」になりました。

聞き分け対決の結果は、私が作成したAIモデルの正解率が「100%」、私の正解率は「84%」ということで、圧倒的なAIの勝利となりました。ノイズが入っていないクリーンな音声データだったとはいえ、このような音の聞き分けが簡単に実現できてしまうと言うのは、すごいことですね。
駆け足で音声の聞き分けについて紹介してきましたが、いかがでしたでしょうか。今回はドラムの音で試してみましたが、実際には音や振動による異常検知など、他への応用も可能なのではないでしょうか。(その場合、他にも様々な考慮が必要になりますが)
今回使用した音声データなどは全て公開しているので、実際に手を動かして試したり、実際に聞き比べを行ってみてくださいね。詳細は、下記の参考情報をご参照ください。
それではまた、次回のコラムでお会いしましょう。
参考情報
今回作成したNotebookのソースコードや音声データ、モデルなど、参考情報を下記に記載しておきます。
ソースコードや各種データ
今回使用した全てのソースファイルや各種データ、環境構築のためのDockerfileはGitHub (tf2-sound-classification-tcn)(外部サイト)で公開しています。
実行結果が同じになるように乱数処理のシード値を固定していますが、GPUを使って学習する部分についてはTensorFlowの仕様上、全く同じ結果にはなりません。そのため、エポック単位のAccuracy、Lossの結果や、学習済みモデルのウェイト値などは実行の度に多少の違いが出ることにご注意ください。
今回の検証には、Docker Hubで公開されているTensorFlowのイメージ(tensorflow/tensorflow:2.4.1-gpu)を利用しています。
Windows上のDockerからGPUを利用する方法については、以前私が書いた記事「Windows上のDockerでGPUを使おう」をご参照いただければと思います。
リンク集
関連するリンクを以下にピックアップしています。(全て外部リンク)
当サイトの内容、テキスト、画像等の転載・転記・使用する場合は問い合わせよりご連絡下さい。
エバンジェリストによるコラムやセミナー情報、
IDグループからのお知らせなどをメルマガでお届けしています。



