
関連するソリューション

業務改革
AI
フェロー 玉越 元啓

はじめに:AIモデルが直面する新たな脅威
AIの社会実装が加速する中、モデルそのものが攻撃対象となる事例が急増しています。従来のネットワークセキュリティでは捉えきれない「モデル固有の脆弱性」が顕在化し、AIセキュリティは独立した技術領域として急速に重要性が高まっています。本稿では、敵対的攻撃、モデル盗用、プライバシー漏洩、モデル反転といった脅威のメカニズムと、それに対抗する防御技術の最前線を解説します。
脅威のメカニズム
今回解説する脅威は以下の4種類です。- 敵対的攻撃
- モデル盗用
- プライバシー漏洩
- モデル反転
敵対的攻撃(Adversarial Examples)の仕組みと事例
技術解説敵対的攻撃は、入力データに微細な摂動(perturbation)を加えることで、AIモデルの予測を意図的に誤らせる手法です。これらの摂動は、通常の人間の視覚や聴覚では認識できないほど小さく、モデルの勾配情報を利用して生成されます。
図1.敵対的攻撃のイメージ

出展:https://www.tensorflow.org/tutorials/generative/adversarial_fgsm
攻撃者はパンダの画像に小さな摂動(歪み)を追加し、その結果、モデルは高信頼度でこの画像をテナガザルとして分類するようになります。
代表的な手法:
- FGSM(Fast Gradient Sign Method):損失関数の勾配の符号に基づいて、1ステップで摂動を加える高速手法。
- PGD(Projected Gradient Descent):FGSMを複数回繰り返すことで、より強力な摂動を生成。
- CW(Carlini & Wagner)攻撃:摂動の不可視性と攻撃成功率を両立する最先端手法。L2ノルム制約下で最適化を行う。
事例:交通標識誤認による自動運転の危険
米国の研究機関による実験では、STOP標識に数ピクセルのノイズを加えることで、画像分類モデルが「速度制限標識」と誤認する事例が報告されました(https://arxiv.org/abs/1707.08945)。これは自動運転車が停止すべき場所で減速のみを行うという危険な挙動につながります。
防御技術
- Adversarial Training:敵対的サンプルを含めた再学習により、モデルのロバスト性を向上。
- Defensive Distillation:教師モデルの出力分布を滑らかにし、摂動への感度を低減。
- Feature Squeezing:入力の情報量を圧縮し、摂動の影響を検出しやすくする。
モデル盗用(Model Stealing)とその対策
技術解説モデル盗用は、API経由で公開されたAIモデルに大量のクエリを送信し、その応答を収集・分析することで、元モデルの挙動を模倣・再構築する攻撃です。攻撃者は、教師なし学習や模倣学習(distillation)を用いて、近似モデルを構築します。
技術自体は、以前ご紹介した蒸留
AIの効率化を実現する蒸留技術~その利点と課題(前編/後編)
https://www.idnet.co.jp/column/page_381.html
https://www.idnet.co.jp/column/page_382.html
を流用したものになります。
図2.モデル盗用のイメージ
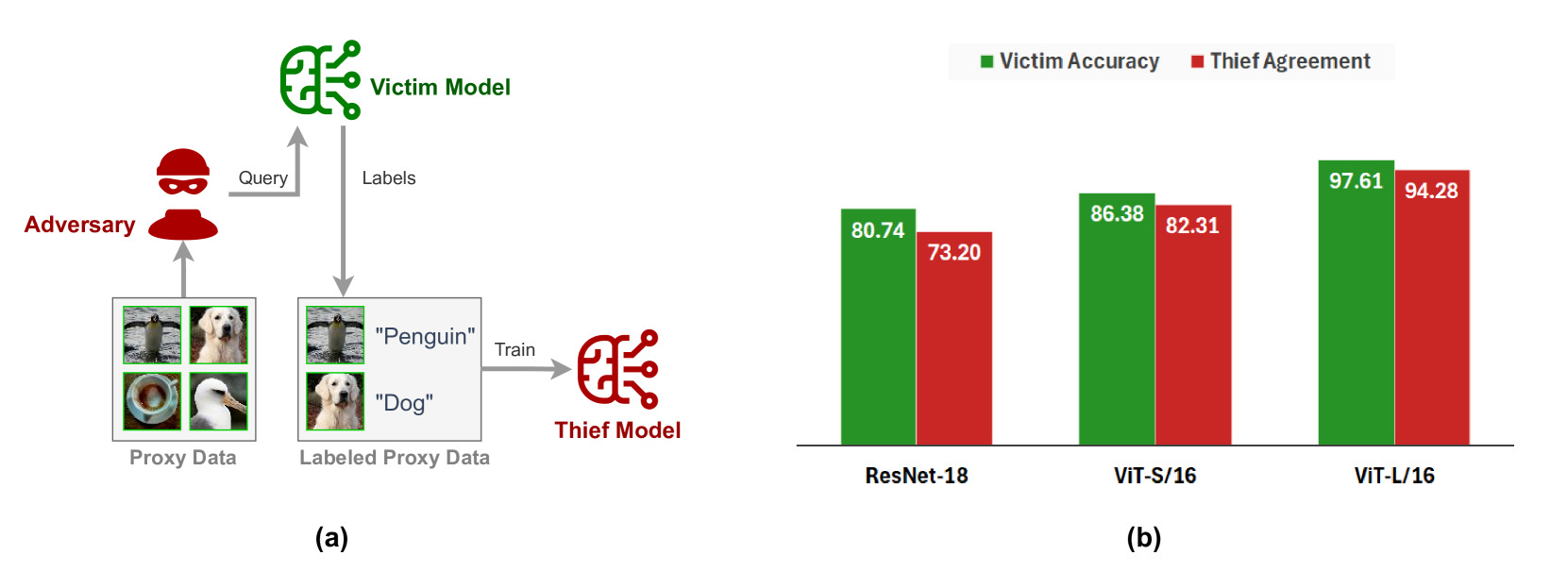
出展:https://arxiv.org/html/2502.18077v1
モデル盗用の検出は非常に困難です。APIは通常、ブラックボックスであり、外部からのアクセスを制限しづらく、出力が確率分布の場合、より多くの情報が漏洩することになります。
事例:自然言語処理APIの盗用
ある企業が提供する感情分析APIに対して、外部研究者が数十万件のクエリを送信し、応答を元に模倣モデルを構築。元モデルと同等の精度を達成し、商用価値が損なわれた事例があります。
具体的には、Amazon Machine Learning や BigML の商用APIに対して数万〜数十万件のクエリを送信し、応答を収集し、ロジスティック回帰、ニューラルネット、決定木などのモデルを高精度で模倣しています。(https://www.usenix.org/system/files/conference/usenixsecurity16/sec16_paper_tramer.pdf)
防御技術
- Top-k出力制限:確率分布の上位k件のみ返すことで情報漏洩を抑制。
- Watermarking:モデルの重みや出力に識別可能な痕跡を埋め込み、盗用検出を可能に。
- Query Monitoring:異常なアクセスパターン(高頻度・広範囲な入力)を検知し、遮断。
メンバーシップ推論攻撃によるプライバシー漏洩
技術解説メンバーシップ推論攻撃は、あるデータがモデルの学習に使われたかどうかを外部から判定する手法です。モデルが学習データに対して過剰に適合している場合、応答の信頼度や分布が異なるため、攻撃者はその差異を利用して推論します。
図3.メンバーシップ推論攻撃のイメージ
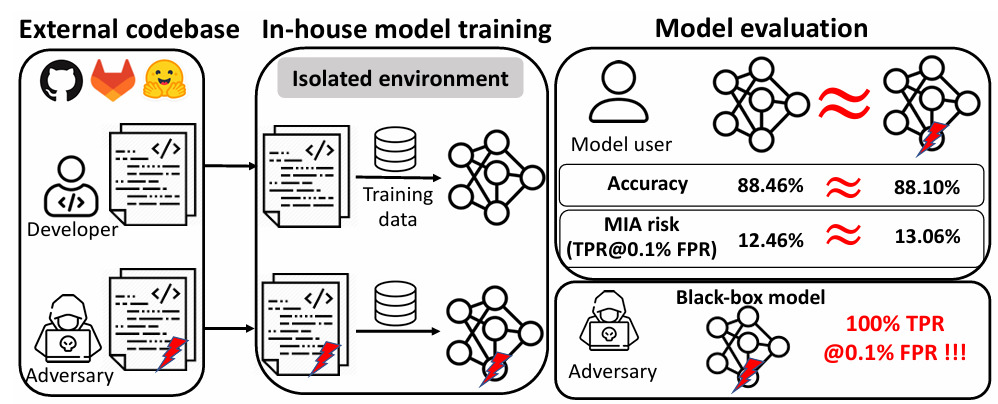
出展:https://www.ndss-symposium.org/wp-content/uploads/2025-41-paper.pdf
攻撃者が特定の入力(例:患者Aの診断データ)をモデルに与えたとき、モデルの応答(信頼度、出力分布など)を分析することで、 「このデータは学習に使われたか否か」を高精度で判定することが可能です。つまり、攻撃者が持っている「候補データ」について、それが学習済みかどうかを判定することが可能となり、個人情報が含まれる候補データを使用してこの攻撃が成功すると、事実上「その人の情報がモデルに含まれている」と言えることになります。
代表的な手法:
- Shadow Models:攻撃者が類似モデルを構築し、学習済み・未学習データの応答差を学習。
- IMIA(Iterative Membership Inference Attack):複数回のクエリを通じて、確信度を高める推論。
事例:医療診断モデルに対する推論攻撃
医療AIが患者の診断履歴を学習している場合、外部からのクエリに対する応答を分析することで、特定患者のデータが学習に使われたかを推論される事例が報告されています(https://link.springer.com/chapter/10.1007/978-981-99-8138-0_2)。これは、個人情報保護法(GDPRなど)に抵触する可能性があります。
防御技術
- Differential Privacy:学習時に統計的ノイズを加え、個別データの影響を希薄化。
- 正則化・Dropout:過学習を抑制し、応答の差異を減少させる。
- Confidence Masking:予測信頼度を非表示にすることで、推論精度を低下させる。
モデル反転攻撃とデータ再構成の脅威
技術解説モデル反転攻撃は、モデルの出力(特に確率分布や中間層の特徴量)から、元の入力データを逆算・再構成する手法です。これは、モデルが入力データの特徴を過剰に保持している場合に発生します。
図4.モデル反転攻撃のイメージ
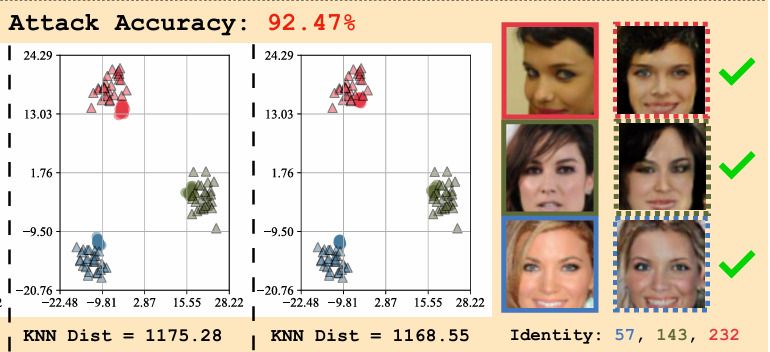
出展:https://openaccess.thecvf.com/content/CVPR2023/papers/Nguyen_Re-Thinking_Model_Inversion_Attacks_Against_Deep_Neural_Networks_CVPR_2023_paper.pdf
顔認識モデル(CelebAデータセット)に対して、出力ベクトルから顔画像を再構成しています。90%以上の攻撃成功率を達成しており、実際の顔画像に酷似した再構成が可能であることを示し、プライバシーリスクが存在することを認識できます。
代表的な手法:
- Gradient Inversion:勾配情報から元データを再構成。
- Activation Leakage:中間層の活性化値から入力特徴を復元。
事例:顔認識モデルからの顔画像再構成
ある顔認識APIに対して、出力ベクトルから逆算することで、元の顔画像を再構成する研究が報告されています。これは、本人の同意なしに顔情報が漏洩する重大なプライバシー侵害です。
防御技術
- 出力制限:中間層の情報や確率分布の詳細を非公開化。
- 情報理論的設計:エントロピーや情報ゲインを最小化することで、再構成可能性を低減。
- Federated Learning + Differential Privacy:分散学習とノイズ付加により、個別データの再構成を困難にする。
実践:FGSMによる攻撃と防御策
(1)攻撃対象のモデルFashion-MNISTという画像分類用の公開データセットを用いて、分類モデルを構築します。28×28ピクセルのグレースケール画像を入力とし、10種類のカテゴリに分類するシンプルなCNNモデルです。
分類モデルの構造
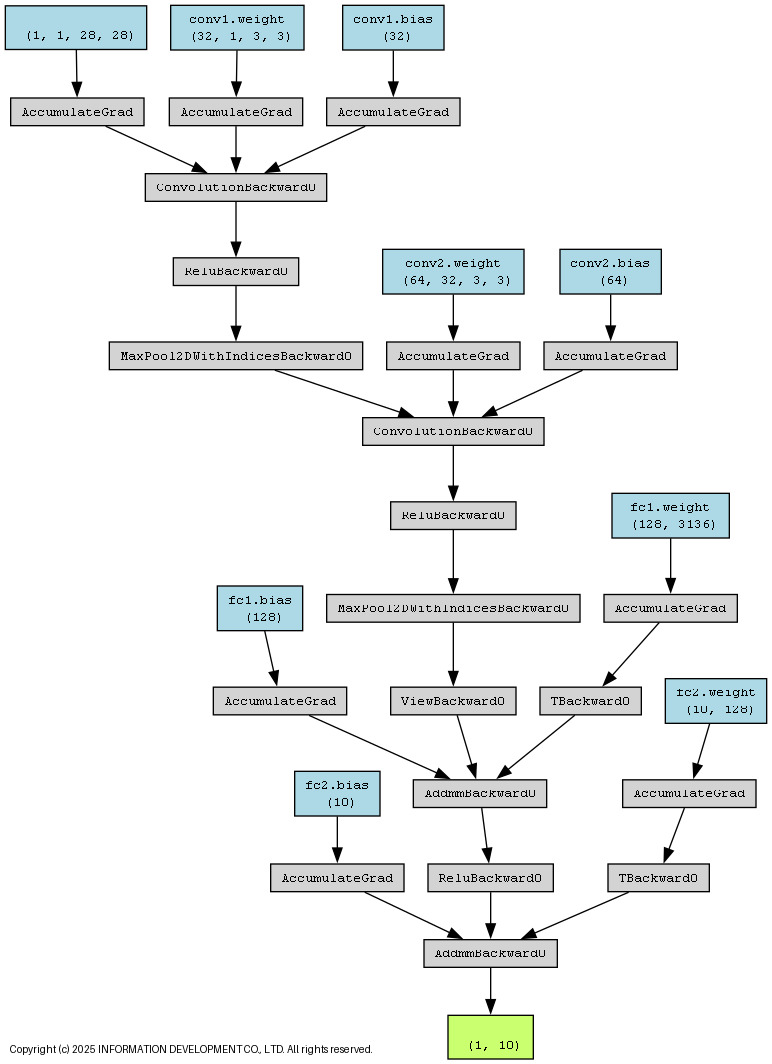
(2)FGSMによる攻撃
def fgsm_attack(image, epsilon, data_grad):
sign_data_grad = data_grad.sign()
perturbed_image = image + epsilon * sign_data_grad
return torch.clamp(perturbed_image, 0, 1)1.sign_data_grad = data_grad.sign()
損失関数に対する画像の勾配の符号(+1, 0, -1)を取得します。これにより、各ピクセルをどの方向に変化させれば損失が増加するかがわかります。 FGSMはこの符号方向に摂動を加えることで効率的に誤分類を誘発します。
2.perturbed_image = image + epsilon * sign_data_grad
元画像に、epsilon 倍の符号付き勾配を加算します。これが敵対的画像となります。epsilon が小さいほど摂動は目立たず、大きいほど攻撃力は増しますが、視覚的に不自然な画像になる可能性があります。
(3)攻撃をうけた画像と結果
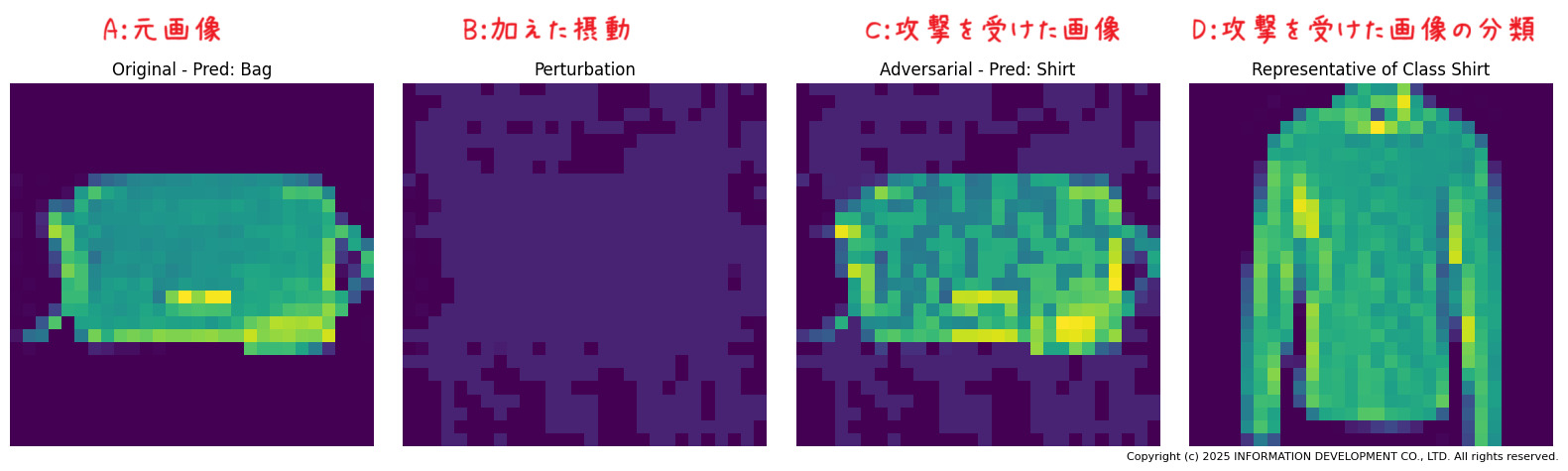
左から順に、
A:元画像(例:カバン)
B:元画像に加えた摂動の差分イメージ
C:FGSM攻撃を受けた画像
D:攻撃を受けた画像に対する分類結果
人間の目にはカバンと認識できる画像が、AIモデルにはシャツとして誤認識されていることがわかります。
(4)防御策
摂動を加えた敵対的画像を訓練データに含めることで、モデルのロバスト性を高め、誤分類を抑止することが可能です。この手法は「敵対的訓練(Adversarial Training)」と呼ばれ、敵対的攻撃に対する基本かつ効果的な防御策の一つです。
全体を通して
攻撃手法を具体的に理解することで、適切な防御策を講じることが可能になります。今回は一部コードまで踏み込んで紹介しましたが、他の攻撃手法や防御技術について詳しく知りたい方は、弊社窓口までお問い合わせください。
AIモデルのセキュリティ強化には、精度や学習効率とのトレードオフが伴います。
たとえば、Adversarial Trainingはモデルの堅牢性を高める一方で、通常の精度が若干低下する可能性があります。
また、Differential Privacyは個人情報保護に有効ですが、学習の収束速度やモデル性能に影響を与えることがあります。
このようなトレードオフは、単なる技術的選択ではなく、ユースケース・法規制・ユーザー体験・事業戦略といった複合的な要因に基づく「設計判断」として捉えるべきです。
企業や開発者は、セキュリティ・プライバシー・精度・性能などの観点からバランス設計を行うことが求められます。
AIセキュリティは、AIの社会実装を支える基盤技術であり、今後ますます重要性を増す分野です。
攻撃手法は日々進化しており、防御技術もそれに応じて高度化しています。
企業は、AIモデルを単なる技術資産ではなく「守るべき知的財産」として捉え、セキュリティ設計を前提としたAI開発体制を構築することが不可欠です。
サンプルコード
FGSMを体験できるサンプルコードです。出力結果や表示内容は一部記事とは異なっています。import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.fc1 = nn.Linear(64 * 7 * 7, 128)
self.fc2 = nn.Linear(128, 10)
self.pool = nn.MaxPool2d(2, 2)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 64 * 7 * 7)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
def fgsm_attack(image, epsilon, data_grad):
sign_data_grad = data_grad.sign()
perturbed_image = image + epsilon * sign_data_grad
return torch.clamp(perturbed_image, 0, 1)
label_map = {
0: "T-shirt/top",
1: "Trouser",
2: "Pullover",
3: "Dress",
4: "Coat",
5: "Sandal",
6: "Shirt",
7: "Sneaker",
8: "Bag",
9: "Ankle boot"
}
transform = transforms.ToTensor()
trainset = torchvision.datasets.FashionMNIST(root='./data', train=True, download=True, transform=transform)
testset = torchvision.datasets.FashionMNIST(root='./data', train=False, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
testloader = torch.utils.data.DataLoader(testset, batch_size=1, shuffle=True)
model = SimpleCNN()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
model = SimpleCNN()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
model.train()
for epoch in range(10):
for images, labels in trainloader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
model.eval()
data_iter = iter(testloader)
image, label = next(data_iter)
image, label = image.to(device), label.to(device)
image.requires_grad = True
output = model(image)
init_pred = output.max(1, keepdim=True)[1]
if init_pred.item() == label.item():
loss = criterion(output, label)
model.zero_grad()
loss.backward()
data_grad = image.grad.data
epsilon = 0.25
perturbed_image = fgsm_attack(image, epsilon, data_grad)
output_adv = model(perturbed_image)
final_pred = output_adv.max(1, keepdim=True)[1]
orig = image.squeeze().detach().cpu().numpy()
adv = perturbed_image.squeeze().detach().cpu().numpy()
fig, axs = plt.subplots(1, 2, figsize=(8, 4))
axs[0].imshow(orig, cmap="gray")
axs[0].set_title(f"Original: {label_map[init_pred.item()]}")
axs[0].axis('off')
axs[1].imshow(adv, cmap="gray")
axs[1].set_title(f"Adversarial: {label_map[final_pred.item()]}")
axs[1].axis('off')
plt.tight_layout()
plt.show()
else:
print("Initial prediction was incorrect; skipping FGSM attack.")当サイトの内容、テキスト、画像等の転載・転記・使用する場合は問い合わせよりご連絡下さい。
エンジニアによるコラムやIDグループからのお知らせなどを
メルマガでお届けしています。



