
関連するソリューション

業務改革
AI
フェロー 玉越 元啓

はじめに
最近、「蒸留」という技術を活用して成果を上げたAIが登場し注目を集めています。例えば、中国のAI企業DeepSeekが、OpenAIの最新モデルに匹敵する性能を持つAIを、わずか10分の1以下のコストで開発しました。また、日本のSakana AIは、新手法「TAID」を用いて小規模な日本語言語モデル「TinySwallow-1.5B」を開発しました。AIの「蒸留」とは、どのような技術なのか。前編・後編の2回にわたり、この蒸留という技術の概要について解説していきます。
前編では、蒸留の概要、利点、欠点、課題などについて解説していきます。
後編では、実際のコードを見て理解していただければと思います。
蒸留のコードは自動生成できず、またコード付きの解説をしている記事も見かけないので(執筆時点2025年2月25日現在、筆者調査限り)、エンジニアの方には特に役立つと思います。
蒸留とは何か?
蒸留とは
AIの「蒸留(Knowledge Distillation)」とは、大きくて高性能なモデルが持つ知識を、より小さく軽量なモデルに移し替える技術です。大きなモデルを「教師モデル」、小さなモデルを「生徒モデル」と呼びます。このプロセスでは、大きなモデルから知識を抽出し、小さなモデルに凝縮します。科学における液体の蒸留に似ていることから、この技術は「蒸留」と名付けられました。液体の蒸留は、液体を加熱して蒸発させ、その蒸気を冷却して再び液体に戻すことで純度を高める方法です。
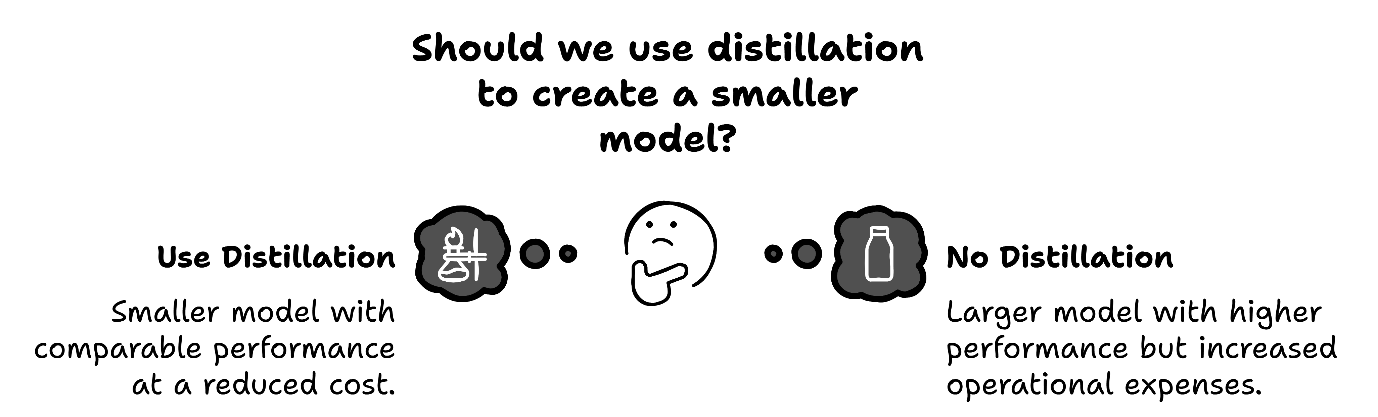 画像出典:https://techcommunity.microsoft.com/blog/aiplatformblog/distillation-turning-smaller-models-into-high-performance-cost-effective-solutio/4355029
画像出典:https://techcommunity.microsoft.com/blog/aiplatformblog/distillation-turning-smaller-models-into-high-performance-cost-effective-solutio/4355029蒸留を知ることで、大規模モデルをそのまま運用するだけでなく、軽量なモデルに作り替えるという新たな選択肢が生まれます。
誕生の歴史
蒸留という手法は、2015年にGeoffrey Hintonが発表した論文「Distilling the Knowledge in a Neural Network」で導入された技術です。この技術により、教師モデルから生徒モデルへの詳細な知識を効率的に移行できることが示されました。発表から現在に至るまでの間に、自己蒸留やクロスドメイン蒸留など、さまざまなアルゴリズムや方法が開発されています。参考:蒸留の核となる計算式
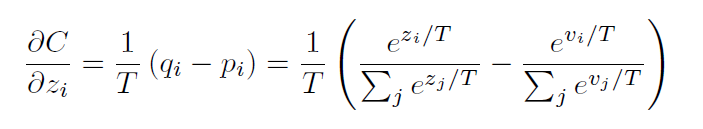
(出典:https://arxiv.org/abs/1503.02531)
関連ニュース
最近話題になった蒸留関連のニュースを2件、紹介します。- DeepSeek:中国のAI企業DeepSeekが、OpenAIの最新モデルに匹敵する性能を持つAIを、わずか10分の1以下のコストで開発した発表があり市場を驚かせました。しかしながら、同社がOpenAIのモデルの出力を利用して、自社のAIを強化したという疑惑があり(Financial Times)、法的および倫理的な問題が提起されています。
- Sakana AI:日本のSakana AIが新手法「TAID(Temporally Adaptive Interpolated Distillation)」を用いて、小規模日本語言語モデル「TinySwallow-1.5B」を開発しました。Qwen2.5-32B-Instructを教師モデルとして、Qwen2.5-1.5B-Instructを生徒モデルとして使用し、日本語テキストデータでさらに事前学習を行ったものです。
蒸留の仕組み
蒸留の概要
蒸留は、大規模な事前学習済みAIモデル(教師モデル)が、より小さく効率的なモデル(生徒モデル)に知識を移す手法です。教師モデルの知識とは、入力データに対して教師モデルが生成する確率分布を指します。生徒モデルは、入力データに対して教師モデルと同じ確率分布を出力できるように学習します。教師モデルは、大量のデータから確率分布の正解を学ぶのに対し、生徒モデルは、既にある正解を学べばよい点が、非常に効率的です。
教師モデル・生徒モデルの特徴やそれぞれの学習について詳しく見ていきましょう。
教師モデルと生徒モデル
蒸留における、大きくて高性能なモデルのことを「教師モデル」、より小さく軽量なモデルのことを「生徒モデル」と呼びます。それぞれの特徴を表にまとめました。表1.教師モデルと生徒モデルの特徴
| 特徴 |
教師モデル |
生徒モデル |
|---|---|---|
| 精度 | 高い精度 | 教師モデルに比べて精度が低くなる可能性がある |
| 構造 |
複雑な構造、多くの層やパラメータ |
パラメータ数が少なく、軽量 |
| トレーニングデータ | 大規模データセットでのトレーニング |
教師モデルからの知識を学習 |
| 計算コスト | 高い計算コスト |
低い計算コスト |
| 推論速度 | 遅い | 高速 |
| リソース依存 |
高性能なハードウェアが必要 |
低リソース環境でも動作可能 |
| 役割 |
知識の抽出と生徒モデルへの転送 |
教師モデルからの知識を学習し、効率的に推論 |
教師から生徒への知識抽出=蒸留
蒸留による生徒モデルの学習は、以下のような順に行われます。1.教師モデルの学習:
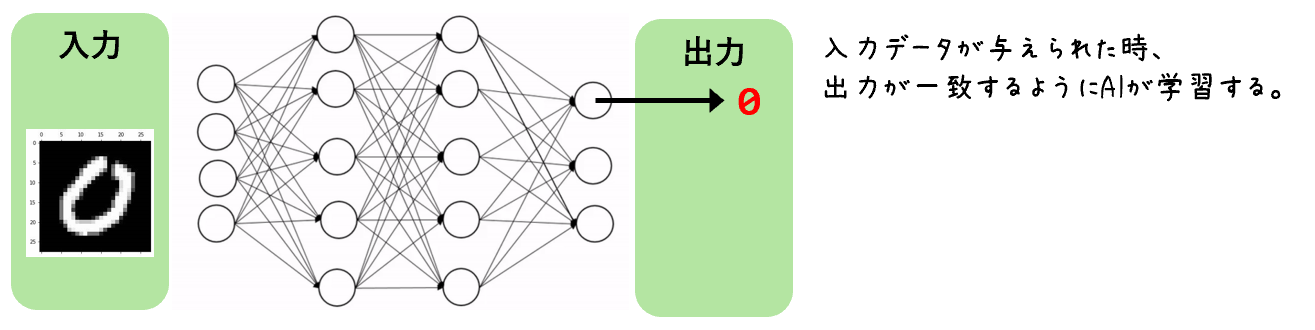 図1.教師モデルの学習イメージ
図1.教師モデルの学習イメージ大規模な教師モデルを、膨大なデータセットを用いて事前に訓練します。訓練とは、AIが計算した最も確率が高い情報が出力と一致するようにモデルのパラメータを調整することです。このモデルは、入力データに対して詳細な確率分布を生成します。
2.教師モデルの出力:
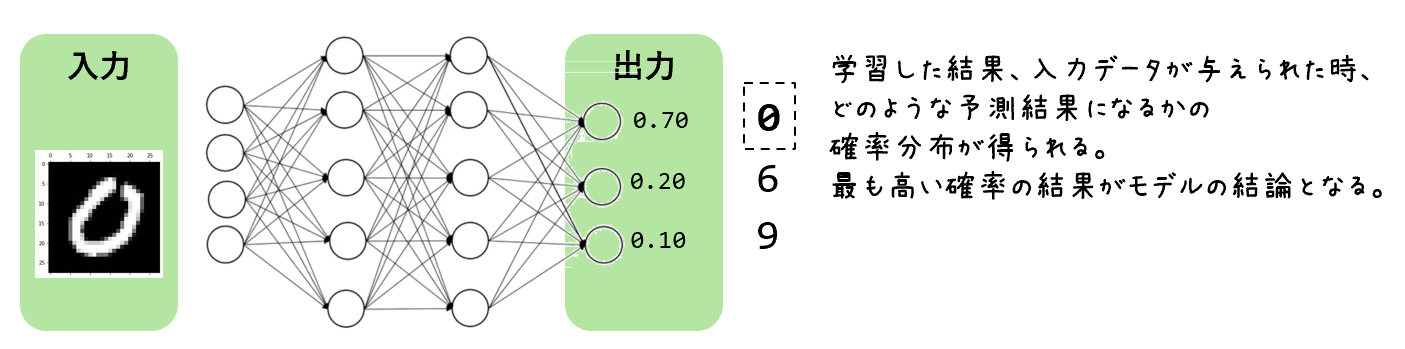 図2.教師モデルの出力イメージ
図2.教師モデルの出力イメージ教師モデルは入力データに対して予測を行い、その出力(ロジットや確率分布)を生成します。これには各クラスに対する信頼度が含まれます。例えば、画像認識タスクでは、教師モデルが「この画像が猫である確率は70%、犬である確率は20%、その他である確率は10%」といった出力を生成します。
3.生徒モデルの学習:
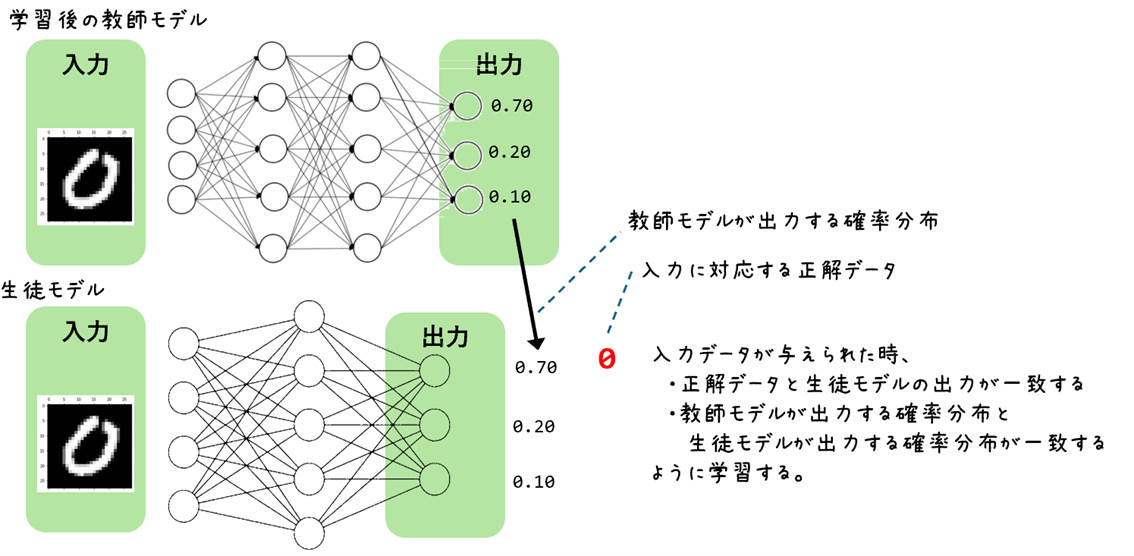 図3.生徒モデルの学習イメージ
図3.生徒モデルの学習イメージ生徒モデルは、教師モデルの出力を目標として学習します。具体的には、生徒モデルは、教師モデルが生成した確率分布を学習します。この過程で、生徒モデルは教師モデルの知識を効率的に吸収し、より小さなモデルサイズで高い性能を発揮できるようになります。
蒸留損失関数
生徒モデルは、教師モデルの出力を目標として学習します。このとき、教師モデルの出力と生徒モデルの出力の間の差(ソフト・ロス)と、正解データと生徒モデルの出力の差(ハード・ロス)を合計したものを蒸留損失関数と呼びます。生徒モデルはこの損失関数が小さくなる、つまり差が少なくなるように学習します。教師モデルの出力が100%正しいわけではないため、正解データも併せて学習することが推奨されます。「蒸留」の利点と欠点、利用する場面
蒸留の利点
- モデルの軽量化
大規模なAIモデルの知識を小型モデルに移す軽量化が可能になります。モデルの小型化ができる主な理由は2つあります。
教師モデルの存在:教師モデルを作成する段階では、最適なモデル構成が不明なことが多いです。しかし、既に教師モデルが存在する場合、そのモデルと同じサイズのモデルで結果が出せることがわかっているため、より小さいモデルにすることが可能です。
効率的な逆算:ある入力に対する出力が既に分かっているため、問題(入力)と答え(出力)がわかった状態から逆算することで、効率的にモデルを作成できます。
- 高速化
モデルが軽量化することで、計算量が減り、高速な推論が可能となります。この成果はスマートフォンやIoT機器などのエッジデバイスで高速な処理をさせる必要があるときやリアルタイムな応答が求められる場合に特に有効です。
- 学習コストの削減
教師モデルが存在する場合、生徒モデルは教師モデルと比べて小型であるため、比較的大規模な計算資源を必要とせず、低コストで高性能なAIモデルを開発できます。
自社モデルを蒸留によって軽量化した事例として、TinyBERTが挙げられます。TinyBERTは、BERT(Bidirectional Encoder Representations from Transformers)モデルを蒸留して作成されたモデルで、以下のような特徴が報告されています。
- モデルサイズの削減:BERTのパラメータ数を約60%削減
- 性能の維持:元のBERTモデルの約97%の性能を維持
- 高速化:推論速度が約60%向上

蒸留の欠点
- 教師モデルの存在
蒸留する元となる教師モデルが存在する必要があります。自分で教師モデルを準備できない場合、2.や3.で挙げる課題が発生します。
- 知識の損失
蒸留過程で元のAIモデルの一部の知識が失われる可能性があります。特に、「ブラックボックス蒸留(Black-Box Distillation)」と呼ばれる、教師モデルとしてブラックボックス化されているサービスを採用する手法では、最終結論のみの学習となり、教師モデルが持つ確率分布を学習することができません。
教師モデルが必ずしも正解を出せているわけではないため、第2、第3の正解候補の知識が失われてしまうのです。
- データ倫理とセキュリティ
蒸留が教師モデルの「コピー」とみなされる可能性があり、著作権や知的財産権に関する問題が発生することがあります。特に、教師モデルがブラックボックス化されている場合、その内部構造やパラメータにアクセスできないため、知的財産権の侵害が疑われることがあります。
また、モデルのブラックボックス性が増すと、判断根拠が不明瞭になり、信頼性が損なわれるリスクがあります。ブラックボックスモデルは、その内部の意思決定プロセスが理解できないため、バイアスやエラーを特定することが難しくなります。これにより、AIシステムの透明性と説明責任が欠如し、特に医療や金融などの重要な分野での使用において問題が生じる可能性があります。
参考:OpenAIは、中国のAIスタートアップDeepSeekが自社の専有モデルを使用してオープンソースの競合モデルを訓練したと非難しています。
https://www.newsweek.com/openai-warns-deepseek-distilled-ai-models-reports-2022802
蒸留を利用する場面
知識蒸留を用いることで、生徒モデルは教師モデルの性能を維持しつつ、より小さなモデルサイズで高い精度を達成することができることがわかりました。以下のような場面で蒸留が利用されます。- 実験と運用:AIで実現できるかを大規模な教師モデルで実験し、実際に運用する場面において、生徒モデルを作成するような使い方をします。これにより、実験段階で得られた高性能を維持しつつ、運用段階での効率性を向上させることができます。
- エッジ端末での利用:特に、エッジ端末でAIモデルを動かしたい場合に、モデルを軽量化する目的で蒸留という手法が採用されています。エッジデバイスは計算資源が限られているため、軽量化されたモデルが必要です。蒸留を用いることで、エッジデバイスでも高性能なAIモデルを実現できます。
まとめ
蒸留技術は、大規模なAIモデルの知識を小型で効率的なモデルに移す手法です。その概要、利点、欠点、そして活用する際の課題についてもご紹介しました。次回は具体的なコードの解説を行います。蒸留技術を実際にどのように実装するか、コードを通じて詳しく説明しますので、お楽しみに!
当サイトの内容、テキスト、画像等の転載・転記・使用する場合は問い合わせよりご連絡下さい。
エンジニアによるコラムやIDグループからのお知らせなどを
メルマガでお届けしています。



