
関連するソリューション

業務改革
AI
フェロー 玉越 元啓

はじめに
ここ何か月かの間に、「蒸留」という技術を活用して成果をあげたAIが登場し世間を賑わせました。AIの「蒸留」とは、どのような技術なのでしょうか。今回はこの蒸留の実装方法について、実際のコードを見て理解していただこうと思います。蒸留のコードは自動生成できず、またコード付きの解説をしている記事も見かけないので(執筆時点2025年2月25日現在、筆者調査限り)、エンジニアの方々には特に役立つと思います。
蒸留とは
AIの「蒸留(Knowledge Distillation)」とは、大きくて高性能なモデルが持つ知識を、より小さく軽量なモデルに移し替える技術です。前者の大きなモデルのことを「教師モデル」、後者の小さなモデルのことを「生徒モデル」と呼びます。詳細は、「AIの効率化を実現する蒸留技術~その利点と課題(前編)」の解説記事をご覧ください。図1.教師モデルから生徒モデルが学習するイメージ
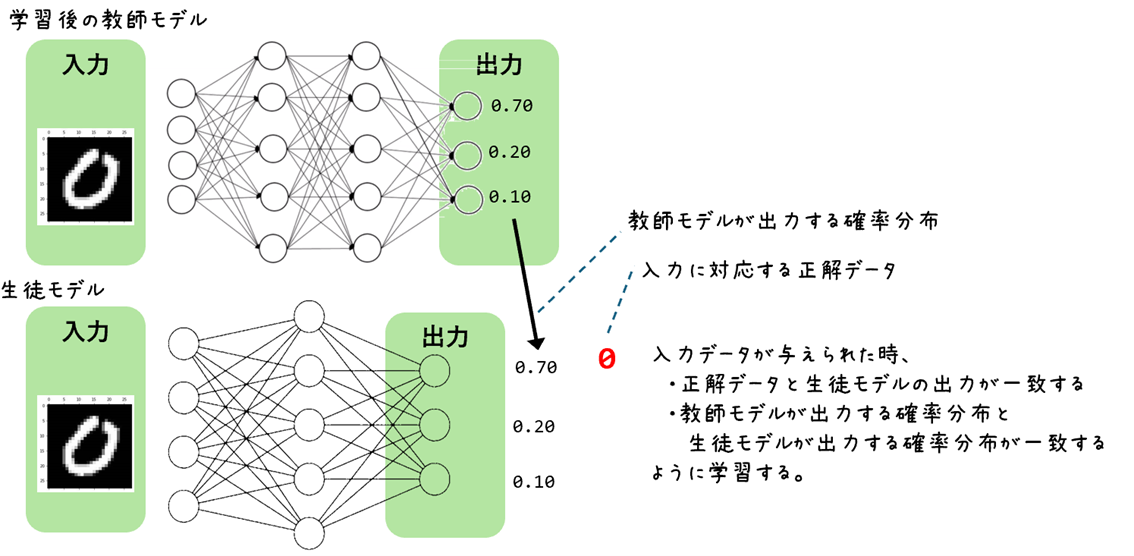
蒸留コード実装のシナリオ
蒸留コード実装に向けたシナリオ
0~9の手書き数字画像から何が書かれているかを予測するOCR機能を実装することとします。最初に、大きな教師モデルを作成します。この教師モデルを蒸留することで、より軽量な生徒モデルを作成することとしました。
軽量化の目標として、教師モデルのパラメータ数を1/3程度まで小型化してみました。
実装の進め方
次の1.~5.のブロックに分けて実装していきます。- 教師モデルの定義、学習
- 生徒モデルの定義
- 蒸留損失関数の定義
- 生徒モデルの学習
- 性能比較
教師モデル
教師モデルは、下の構成のDNN(ディープニューラルネットワーク)としました。- 入力層: 1層(784)
- 隠れ層: 3層(256×128×64)
- 出力層: 1層(10)
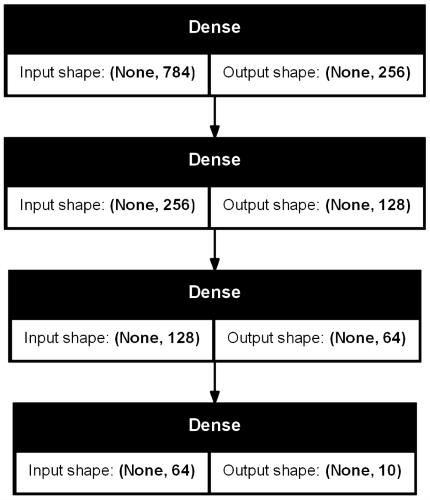
DNNの総パラメータ数は、242,762となります。パラメータ数の計算式は以下のとおりです。
- 入力層から最初の隠れ層へのパラメータ数
重み(784×256)+バイアス(256)=200,960 - 1番目の隠れ層から2番目の隠れ層へのパラメータ数
重み(256×128)+バイアス(128)=32,896 - 2番目の隠れ層から3番目の隠れ層へのパラメータ数
重み(128×64)+バイアス(64)=8,256 - 3番目(最後)の隠れ層から出力層へのパラメータ数
重み(64×10)+バイアス(10)=650
(784×256+256)+(256×128+128)+(128×64+64)+(64×10+10)=242,762
生徒モデル
生徒モデルは、下の構成のDNNとしました。- 入力層: 1層(768)
- 隠れ層: 2層(64×32)…教師モデル(256×128×64)より軽量化!
- 出力層: 1層(10)
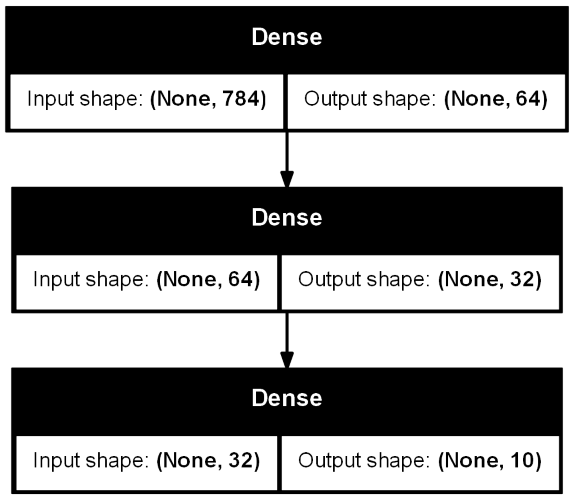
総パラメータ数は、52,650です。教師モデルの約1/5のサイズとなります。蒸留により、かなり小さくしてみました。結果がどうなるか見てみましょう。
入力層(768)と出力層(10)は教師モデルと生徒モデルで同じとなります。
コードのポイント解説
蒸留損失関数の概要
生徒モデルは、教師モデルの出力を目標として学習します。このとき、教師モデルの出力と生徒モデルの出力との間の差(ソフトターゲットの損失、(ソフトロス))と正解データと生徒モデルの出力の差(ハードターゲットの損失(ハードロス))を表したものを蒸留損失関数と呼びます。図4.ソフトロスの計算式
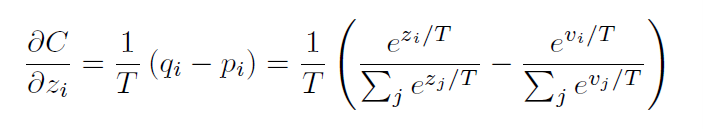
(出典:「Distilling the Knowledge in a Neural Network」)
この、蒸留損失関数の実装が、蒸留の一番のポイントとなります。
また、教師モデルの出力が100%正しいわけではありません。ハードロスを考慮して正解データも併せて学習するようにしていきます。
蒸留損失関数の実装
教師モデルが出力する確率分布と生徒モデルの出力する確率分布を比較して損失を計算する関数です。蒸留のポイントは、この関数に詰まっています。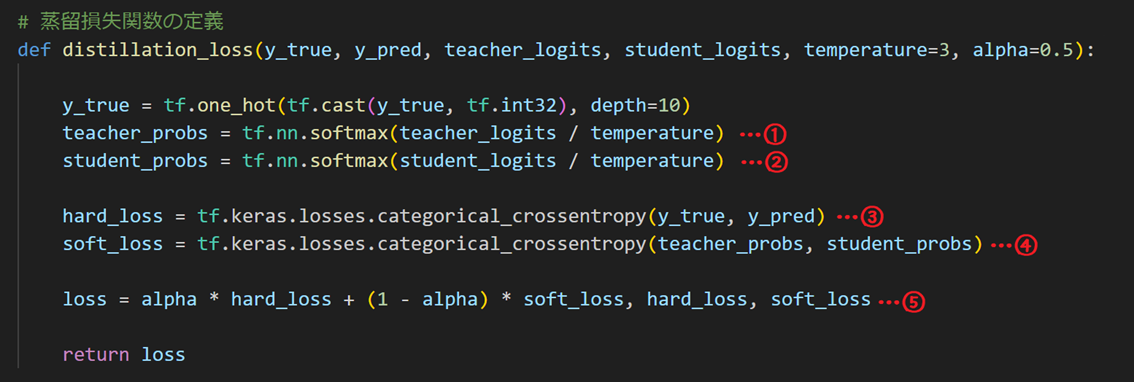
受け取っている引数の意味は下のとおりです。
y_true: 正解ラベル
y_pred: 生徒モデルの予測
teacher_logits: 教師モデルのロジット
student_logits: 生徒モデルのロジット
temperature: 温度 ※
alpha: ハードターゲットとソフトターゲットの損失を調整するための重み付け
※温度(temperature)は、確率分布のスムージングを調整するためのパラメータです。
- 教師モデルのロジット(未スケーリングの出力)を温度スケーリングし、ソフトマックス関数を適用して確率分布に変換します。
- 生徒モデルのロジットも同様に温度スケーリングし、ソフトマックス関数を適用して確率分布に変換します。
- ハードターゲットの損失である正解ラベルと生徒モデルの予測との間のクロスエントロピー損失を計算します。
- ソフトターゲットの損失である教師モデルと生徒モデルの確率分布との間のクロスエントロピー損失を計算します。
- αを用いてハードターゲットとソフトターゲットの損失を調整し、総損失を計算します。
生徒モデルの学習=カスタム・トレーニング・ループ
フレームワークが用意している損失関数ではないため、生徒モデルが学習する処理をコーディングする必要があります。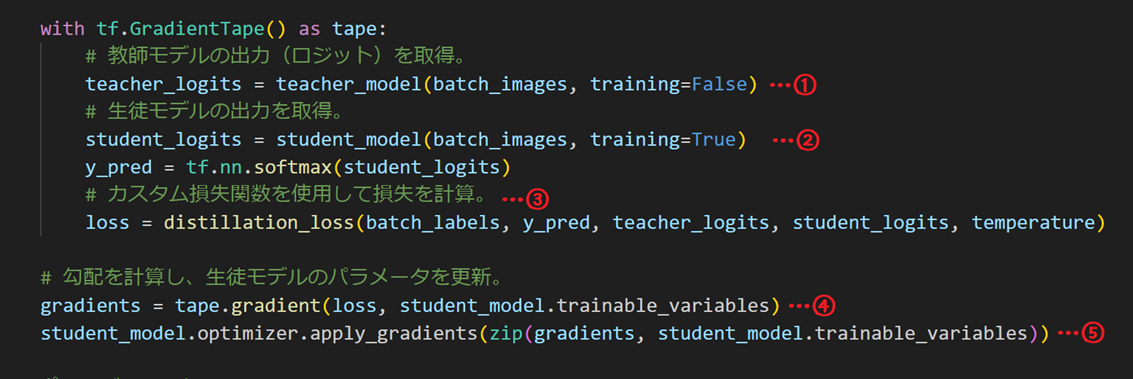
処理の流れは次のとおりです。
- 教師モデルの出力(ロジット)を得る
- 生徒モデルの出力(ロジット)を得る
- 蒸留損失関数で損失を計算
- 損失から勾配※を計算
- 勾配をもとに生徒モデルのパラメータを調整
- 1.~5.を繰り返す
実行結果の例
今回のコードを実行した結果の一例です。教師モデルと生徒モデルの正答率を出力しています。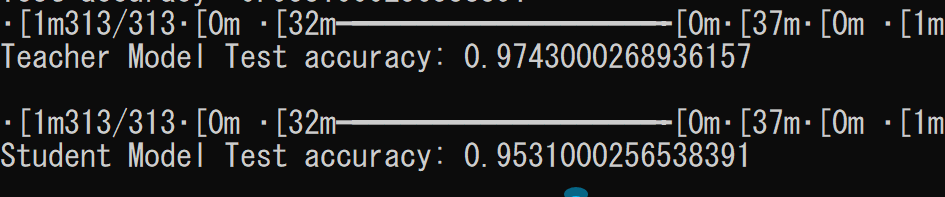
- 教師モデル: パラメータ数 242,762、正解率 97.4%
- 生徒モデル: パラメータ数 52,650、正解率 95.3%
なお、実行環境等により同じ結果になるとは限らないことご理解ください。

まとめ
蒸留というモデルの軽量化技術を使い、エッジで動作させるAIの使い勝手を高められることがわかりました。パラメータ数が少なければ、モデルのサイズも小さくなり、実行時間や消費電力も少なくなります。AIを活用させる場面に応じて、蒸留という選択ができるようになるはずです。エンジニア・学生の方が学習・コードを改良するにあたっては、以下の実装にチャレンジしてください。
- ミニバッチを導入
大規模モデルの蒸留においては、メモリ効率と計算効率を向上させるためにミニバッチが必要です。ミニバッチを使用することで、GPUやTPUの並列処理能力を最大限に活用することができます。
- アーリーストッピングを追加
アーリーストッピングを追加することで、過学習を防ぎ、訓練時間を短縮できます。モデルの性能が一定期間改善しない場合に訓練を停止することで、最適なモデルを得ることができます。
- 生徒モデルの学習においてバリデーションデータを含める
バリデーションデータを含めることで、モデルの一般化能力を評価し、過学習を防ぐことができます。バリデーションデータを使用することで、モデルの性能をより正確に評価できます。
コードの全文
import tensorflow as tf
from tensorflow.keras import layers, models, Input
from tensorflow.keras.datasets import mnist
# MNISTデータセットの読み込み
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# データの前処理
train_images = train_images.reshape((60000, 28 * 28)).astype('float32') / 255
test_images = test_images.reshape((10000, 28 * 28)).astype('float32') / 255
epochs = 10
batch_size = 64
print('\n教師モデルのトレーニング')
# 教師モデルの定義とトレーニング
teacher_model = models.Sequential([
Input(shape=(784,)),
layers.Dense(256, activation='relu'),
layers.Dense(128, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(10, activation='softmax')
])
teacher_model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
teacher_model.fit(train_images, train_labels, epochs=epochs, batch_size=batch_size, validation_split=0.2)
print('\n生徒モデルのトレーニング')
# 生徒モデルの定義
student_model = models.Sequential([
Input(shape=(784,)),
layers.Dense(32, activation='relu'),
layers.Dense(16, activation='relu'),
layers.Dense(10, activation='softmax')
])
# 蒸留損失関数の定義
def distillation_loss(y_true, y_pred, teacher_logits, student_logits, temperature=3, alpha=0.5):
y_true = tf.one_hot(tf.cast(y_true, tf.int32), depth=10)
teacher_probs = tf.nn.softmax(teacher_logits / temperature)
student_probs = tf.nn.softmax(student_logits / temperature)
hard_loss = tf.keras.losses.categorical_crossentropy(y_true, y_pred)
soft_loss = tf.keras.losses.categorical_crossentropy(teacher_probs, student_probs)
loss = alpha * hard_loss + (1 - alpha) * soft_loss # , hard_loss, soft_loss
return loss
# 生徒モデルのコンパイル
student_model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# カスタムトレーニングループ
# バッチごとに教師モデルの出力を取得し、生徒モデルをトレーニングする
num_batches = len(train_images) // batch_size
temperature = 3
for epoch in range(epochs):
print(f'Epoch {epoch+1}/{epochs}')
# 各エポックでバッチごとにデータを取得。
for i in range(num_batches):
batch_start = i * batch_size
batch_end = (i + 1) * batch_size
batch_images = train_images[batch_start:batch_end]
batch_labels = train_labels[batch_start:batch_end]
with tf.GradientTape() as tape:
# 教師モデルの出力(ロジット)を取得。
teacher_logits = teacher_model(batch_images, training=False)
# 生徒モデルの出力を取得。
student_logits = student_model(batch_images, training=True)
y_pred = tf.nn.softmax(student_logits)
# カスタム損失関数を使用して損失を計算。
loss = distillation_loss(batch_labels, y_pred, teacher_logits, student_logits, temperature)
# 勾配を計算し、生徒モデルのパラメータを更新。
gradients = tape.gradient(loss, student_model.trainable_variables)
student_model.optimizer.apply_gradients(zip(gradients, student_model.trainable_variables))
# エポックごとの評価
test_loss, test_acc = student_model.evaluate(test_images, test_labels, verbose=0)
print(f'Test accuracy: {test_acc}')
print('\n')
test_loss, test_acc = teacher_model.evaluate(test_images, test_labels)
print(f'Teacher Model Test accuracy: {test_acc}\n')
# 最終評価
test_loss, test_acc = student_model.evaluate(test_images, test_labels)
print(f'Student Model Test accuracy: {test_acc}')
当サイトの内容、テキスト、画像等の転載・転記・使用する場合は問い合わせよりご連絡下さい。
エンジニアによるコラムやIDグループからのお知らせなどを
メルマガでお届けしています。



