
黒住 好忠
こんにちは。テクニカルスペシャリストの黒住です。
昨年(2022年)あたりから、Generative AI(生成AI)が世界中で注目を集めています。以前のAIは専門家や関係者に限られた部分も多かったのですが、生成AIは一般のユーザーにも広く受け入れられています。
生成AIの中では、MidjourneyやStable Diffusionなどに代表される「画像を生成するAI」と、ChatGPTのような「文章を生成するAI」が多かったのですが、最近では「音楽を生成するAI」も増えてきました。
今回は、2023年6月9日に発表された「音楽生成AI」について紹介したいと思います。
生成AIとは
生成AIは、画像や文章などを「新しく作り出すことができるAI」のことを指しており、「ジェネレーティブAI(Generative AI)、生成系AI、生成型AI」などと呼ばれることもあります。
2022年8月に、文章から画像を生成するStable Diffusionがオープンソースで公開されたことをきっかけに、画像生成AIが大きく広がりました。現在では、Midjourney、Stable Diffusion、DALL-E、Fireflyなど、数多くの画像生成AIが登場しています。
画像生成AIを使うと「under the sea」というような文字での指示を元に、以下のような画像を生成できるようになります。

2022年11月には、ChatGPT(文章系の生成AI)が公開されたことを受け、生成AIが過去にないスピードで広く認知されるようになりました。ChatGPTは「文章でAIと会話」できる特徴があるため、AI活用のハードルが大きく下がりました。
現在では、ChatGPT、Bing AI、Bardなどの各種サービスの他、GPT-xや数多くの大規模言語モデル(LLM:Large Language Model)が登場しています。

音楽生成AIの登場
音楽を生成するAIは、まだ数が少ないのですが、2023年1月にGoogleが「MusicLM」を発表しています。そして、2023年6月9日にMetaから「MusicGen」が公開されました。
MusicGenは、MusicLMとは異なるアプローチを採用しており、現時点の音楽生成AIでは最も品質の高い音楽を生成できるモデルだと思われます。
MusicGen
新しく公開されたMusicGenは、「文章の内容から音楽を生成」するAIです。
例えば「drum and bass beat with intense percussions(激しいパーカッションのドラムとベースのビート)」という文章から、その指示に合わせた音楽を生成できます。また、文章と併せて「口笛や鼻歌などの実際の音声」でメロディーを指定する事も可能です。
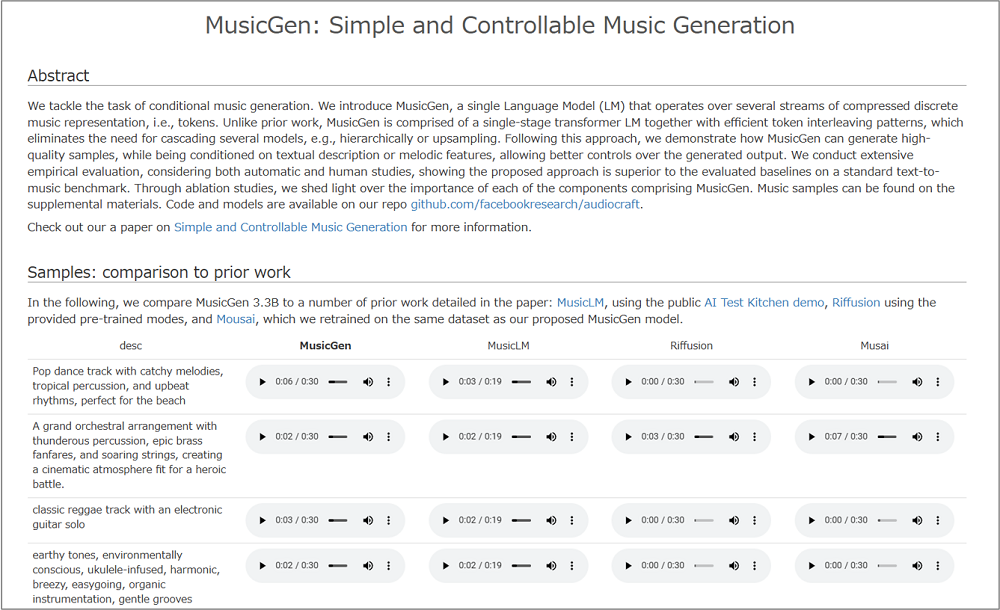
実際にMusicGenで生成された音楽のサンプルが、MusicLMなど他の音楽生成AIと聞き比べできる形で公開されています。MusicLMも良い感じで音楽は生成できているのですが、今回新しく登場したMusicGenの方が、より洗練されている感じを受けます。
MusicGenのサンプル(外部リンク): https://ai.honu.io/papers/musicgen/
MusicGenは、ソースコードやモデルファイルも公開されているので、誰でも「実際に触って独自の音楽を生成」できます。
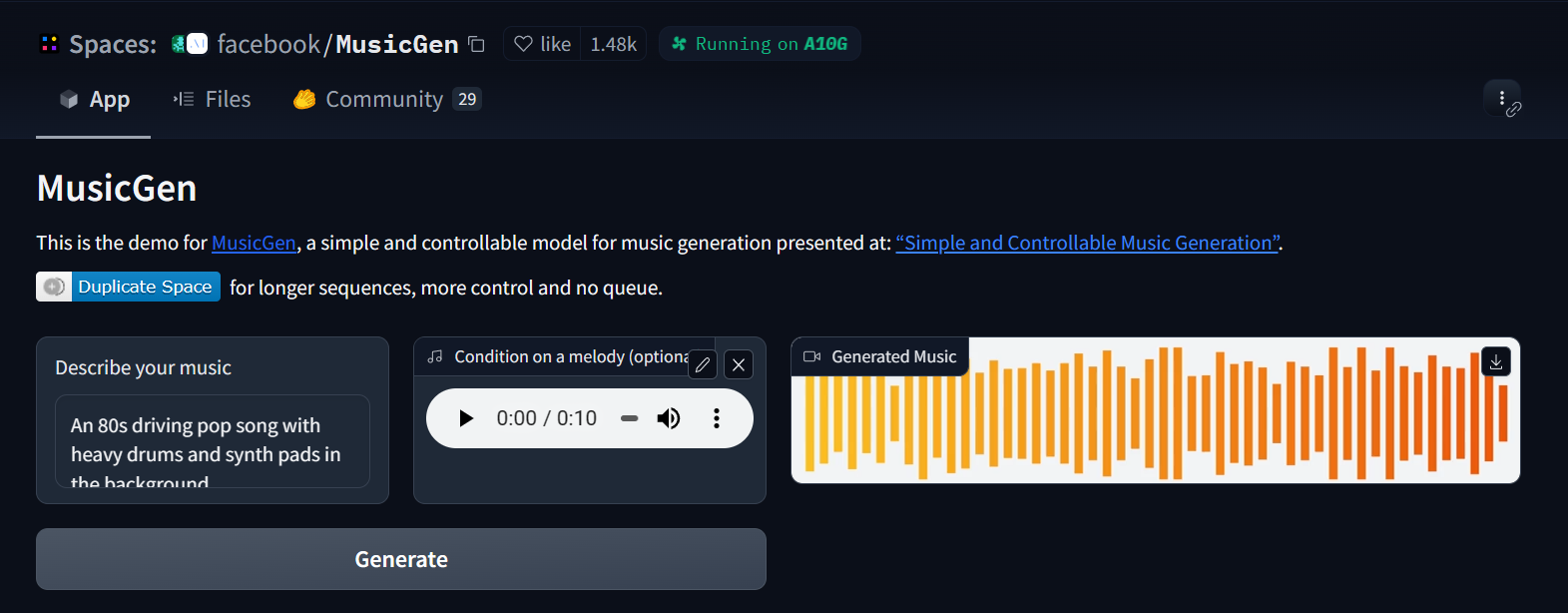
プログラムからMusicGenを利用する事も可能ですが、画面から操作可能なサンプルも提供されているので、プログラミングが苦手な方は、HuggingFace経由で公開されているサンプルページでMusicGenを利用できます。
HuggingFaceのデモ(外部リンク): https://huggingface.co/spaces/facebook/MusicGen
MusicGenの詳細
上記のデモページでは基本的な機能しか提供されていませんが、独自にプログラムを作成したり、MusicGenのソースコードに含まれているデモプログラムを直接実行したりすれば、更に細かい機能が利用できます。
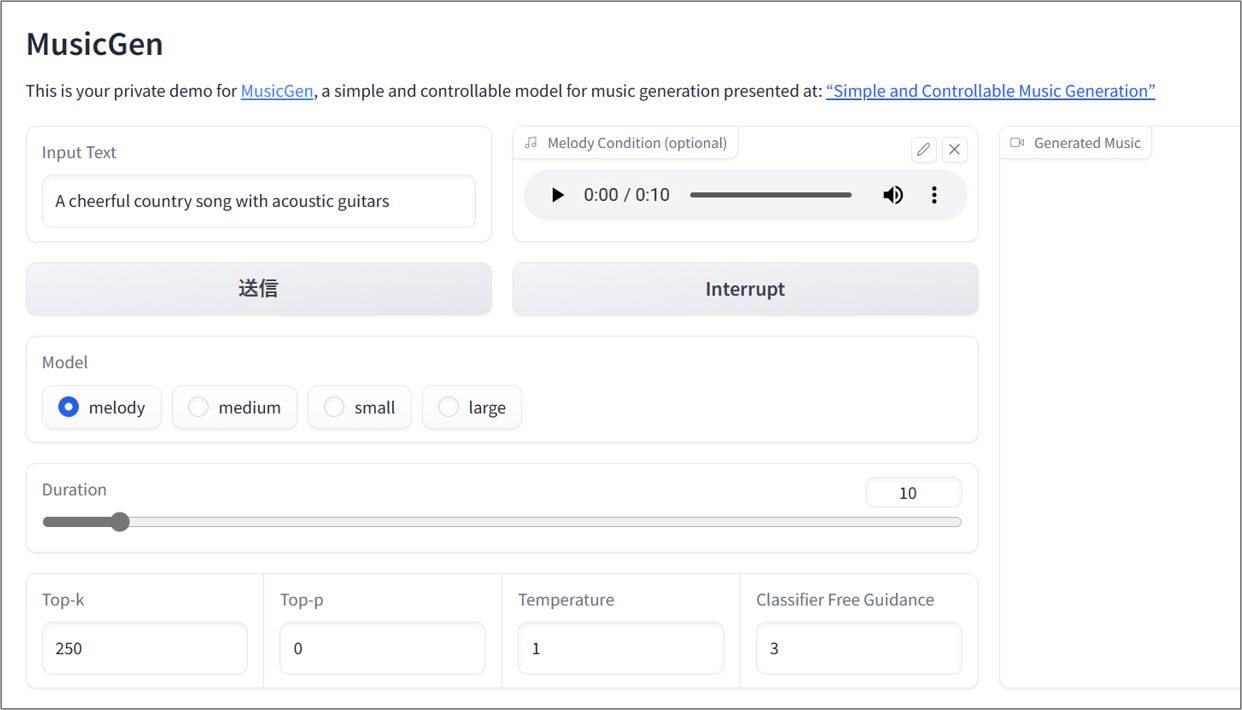
HuggingFaceのデモでは「melody」というモデルしか利用できませんが、独自に動かす場合は、以下4種類のモデルが利用できます。なお、melodyモデルは「medium」と同じ規模(1.5B)の中規模モデルになります。品質が最も高いのは、パラメーターサイズが3.3Bの「large」モデルになりますが、動作させるためには、GPUのVRAMが15~16GB程度必要になります。
- melody:文章による指示+鼻歌などの音声による指定も可能なモデル(1.5B)
- small:300Mの小規模モデル。文章による指示のみ
- medium:1.5Bの中規模モデル。文章による指示のみ
- large:3.3Bの大規模モデル。文章による指示のみ
また、この記事を執筆している2023年6月22日時点では未公開ですが、近いうちに独自データでMusicGenを学習させるためのコードなども提供されるようです。
最後に
画像系や文章系では既に多くの生成AIが登場していますが、それ以外の分野でも、今回ご紹介したMusicGenのように多くの研究が行われています。
中には、2秒程度の音声を聞かせるだけで、その声で文章を自由に読み上げできるような研究成果も発表(意図しない使われ方をする可能性があるため一般公開は行われていない)されています。
今後も、一般ユーザーを含めてAIが急速に広がると思いますが、その中で利用者のAIリテラシーやモラルに関する課題にも真剣に取り組んでいく必要がありますね。
それではまた、次回のコラムでお会いしましょう。
リンク集
本記事に関連するリンクを以下にまとめて記載します。(全て外部リンクです)
当サイトの内容、テキスト、画像等の転載・転記・使用する場合は問い合わせよりご連絡下さい。
エバンジェリストによるコラムやIDグループからのお知らせなどを
メルマガでお届けしています。




